این متن به شما آموزش میدهد که چطور با داشتن ۱۰-۱۲ تصویر از سوژهٔ خود و تکنیک LoRA با Flux مدلی بر طبق آن بسازید تا از سوژه در حالات و مکانهای مختلف با کمک مدلهای هوش مصنوعی تصویر ایجاد کنید.
 |
|---|
پیشنیازها
- کارت اعتباری ویزا. حداقل ۵ دلار. برای پرداخت هزینهٔ مدلسازی و تولید عکس. من کارت اعتباری خودم را از سایت ایرانیکارت تهیه کردم.
- اکانت سایت Replicate.com (رایگان)
- اکانت سایت Huggingface.co (رایگان)
- حداقل ۱۲ عکس از شخصیت مورد نظر. (بهتر است عکسها با پسزمینهٔ سفید و در زاویههای مختلف باشند)
خطر دوبارهکاری!
این آموزش بسیار مشابه ساختن مدل و خلق تصویر با SDXL است. اگر آن را خواندهاید، میتوانید مراحل این آموزش را به سرعت رد کنید.
قدم اول: مقدمات
بعد از ساختن حساب کاربری وارد تنظیمات کاربری خود در سایت Replicate شوید و منوی Billing را باز کنید. اطلاعات کارت اعتباری خودتان را از طریق این صفحه وارد کنید. با استفاده از جعبهٔ متن پایین بخش Spend Limit هم میتوانید یک سقف برداشت از حساب خودتان تعیین کنید.
هزینههای ساخت مدل و تولید خروجی متن یا عکس در صفحهٔ Pricing سایت آمده است. برای نیاز ما و طبق تجربه، ساخت هر مدل حدود ۳.۲۱ دلار و هزینهٔ تولید هر عکس با مدل ساخته شده ۳ سنت خرج دارد.
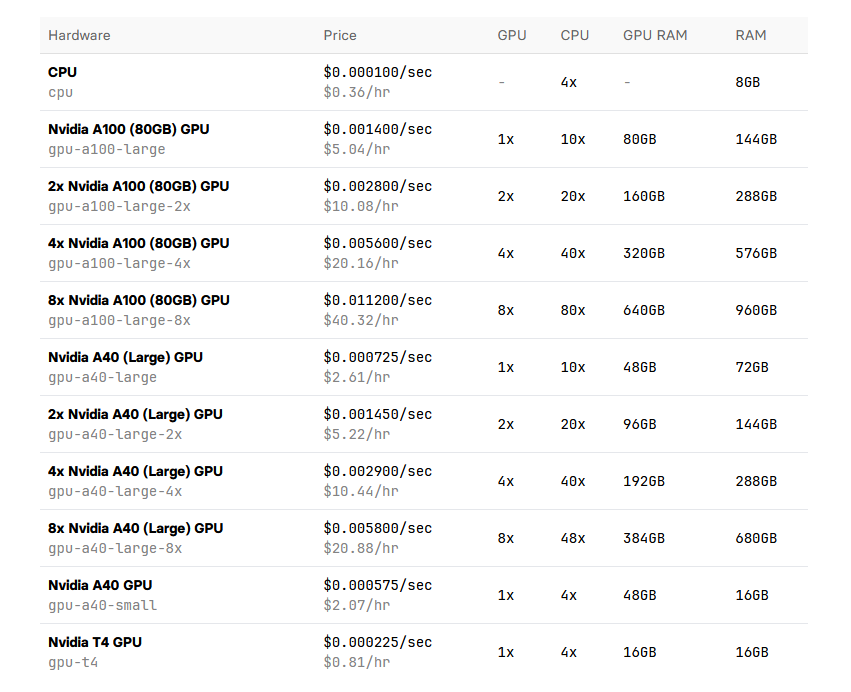
مدل Flux که قصد ساختن آن را داریم، با Nvidia A100 و تکنیک LoRA آموزش داده میشود. یادگیری مدل حدود ۳۰ دقیقه طول میکشد. تولید تصویر هم با کانفیگ یکسان و حدود ۲۰ ثانیه زمان میبرد.
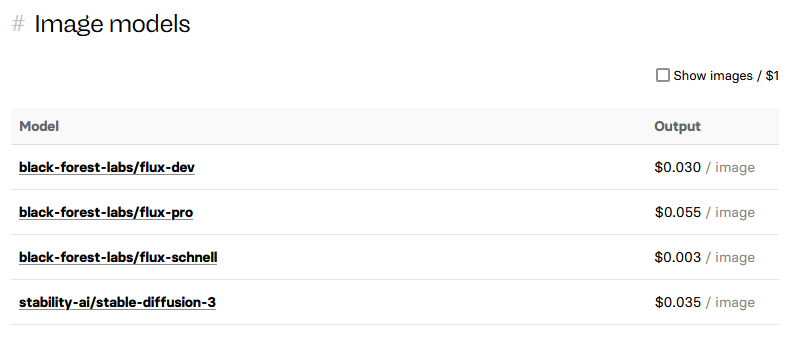
برای ساختن تصاویر سه مدل پایه با کیفیتهای متفاوت وجود دارند. ترجیح ما استفاده از مدل flux-dev برای کیفیت و قیمت بهصرفه است.
قدم دوم: ساختن مدل
برای ساختن مدل ابتدا باید عکسهای مرجع را جمعآوری کنیم. در این پروژه ۱۳ عکس مختلف از شهید مصطفی چمران از طریق اینترنت جمعآوری شد. پس از جمعآوری عکسها، نوبت به نامگذاری آنها میرسد. نامگذاری عکسها باید به فرمت باشد:
a_photo_of_TOK.jpg/png/...
که در آن TOK همان عبارتی است که میخواهیم به مدل اضافه کنیم. مقدار TOK باید یک اسم خاص باشد تا با باقی عبارات مدل اشتباه گرفته نشود. مثل CHMRN یا MCHRAN یا هر عبارت یکتای دیگری. در اینجا ما با خود عبارت chamran عکسها را مشخص کردیم. برای جلوگیری از دوبارهکاری، میتوان همهٔ عکسها را انتخاب کرد و بعد با استفاده از کلید F2 اسم یکی از آنها را به a_photo_of_chamran.jpg تغییر داد. در اینصورت خود ویندوز به همهٔ آنها یک پسوند عددی اضافه میکند.
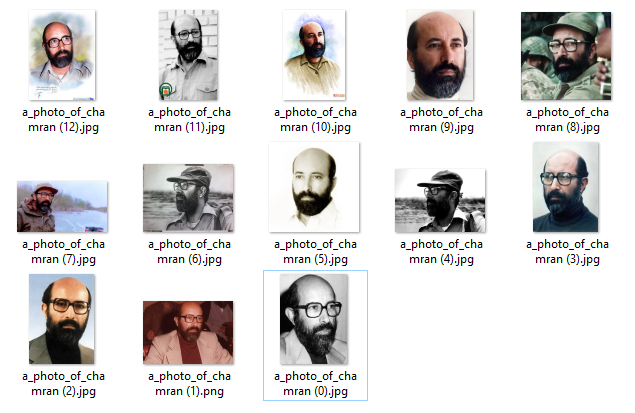
بعد از جمعآوری عکسها، همهٔ آنها را داخل یک فایل Zip فشرده میکنیم. این ورودی ما به مدل است.
کپشن زدن برای عکسها
در صورتی که میخواهید مدل شما عملکرد دقیقتری داشته باشد، میتوانید همراه هر عکس یک فایل با فرمت txt ایجاد کنید که در آن عکس توصیف شده است. همچنین برای توصیف عکسها میتوانید از مدلهایی مثل blip هم استفاده کنید.
برای ساختن مدل از ورودیها، وارد Replicate میشویم و lucataco/ai-toolkitرا پیدا میکنیم. این جعبهابزار فایلی برای ما میسازد که عبارت chamran را به مدل میفهماند. داخل صفحهٔ جدید تبِ Train را انتخاب میکنیم.
(داخل پرانتز: برای تِرِین مدل میتوانید از ostris/flux-dev-lora-trainer هم استفاده کنید؛ اما در زمان نگارش این مطلب امکان آپلود عکس به آن وجود ندارد.)

برای مقدار destination، گزینهٔ Create new model را انتخاب میکنیم و اسم دلخواهی برای مدل خودمان انتخاب میکنیم. مثلاً من flux-lora-character-chamran را انتخاب کردهام.
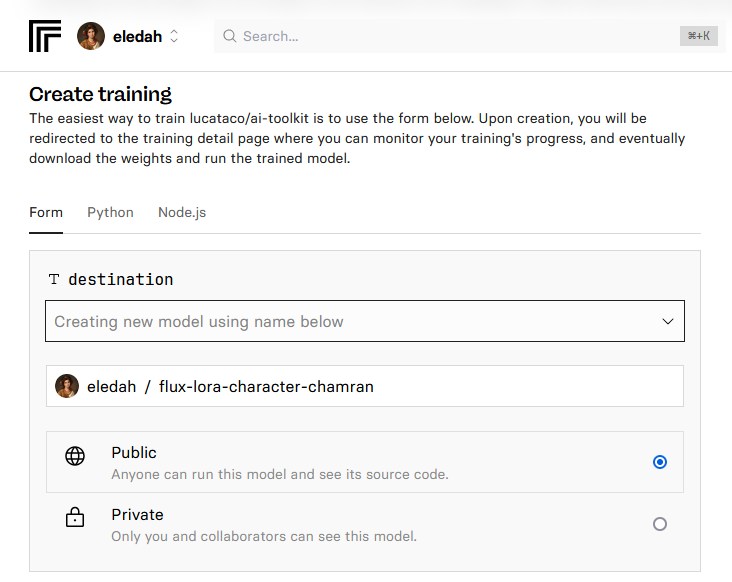
در گام بعدی، فایل Zip عکسهای انتخابی را آپلود میکنیم.
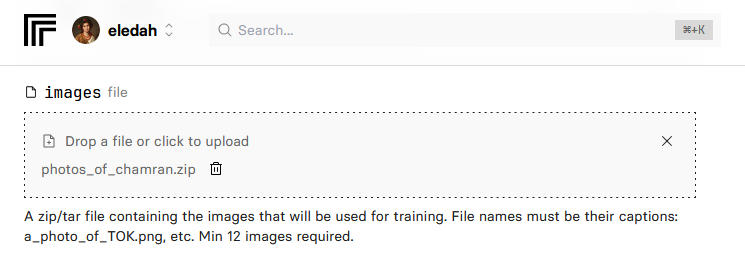
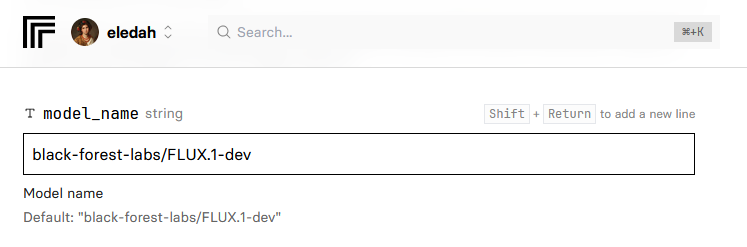
برای مقدار model_name، همان black-forest-labs/FLUX.1-dev را دستنخورده باقی میگذاریم.
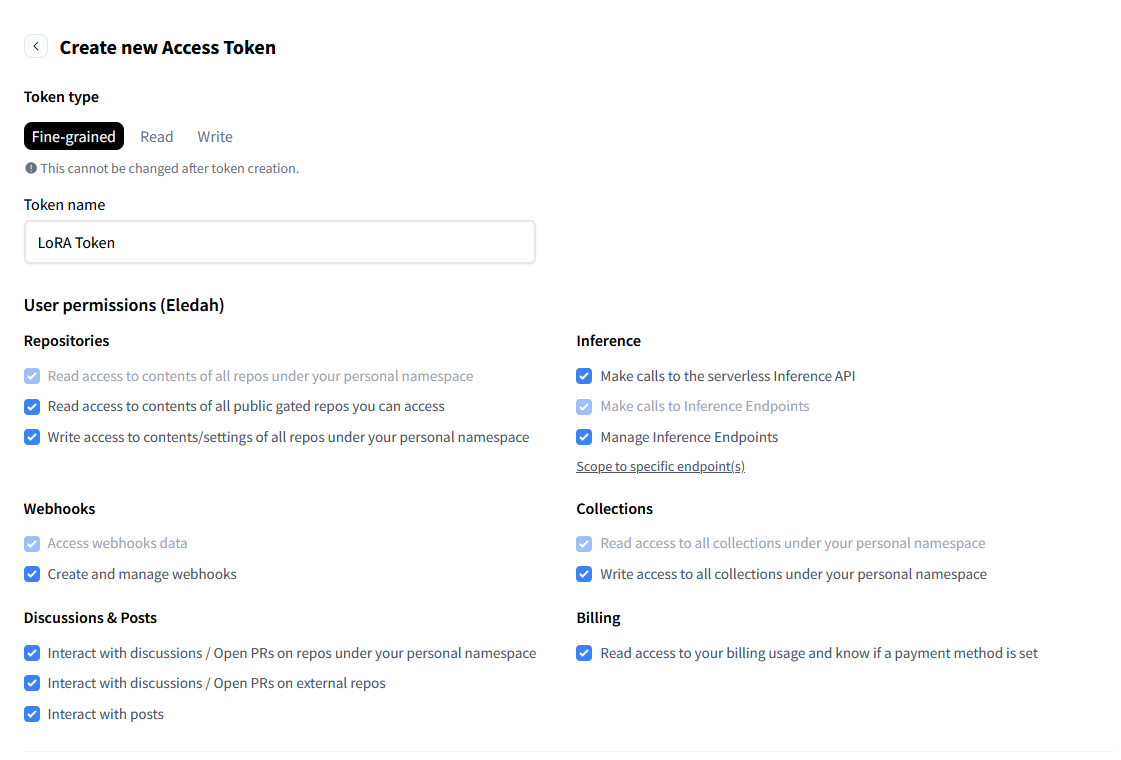
برای مقدار hf_token، باید به صفحهٔ تنظیمات خود در سایت huggingface بروید. منوی Access Tokens را انتخاب کنید و گزینهٔ Create New Token را بزنید. برای تنظیمات محض اطمینان همهٔ تیکها را مثل پایین بزنید و یک اسم دلخواه برایش انتخاب کنید.
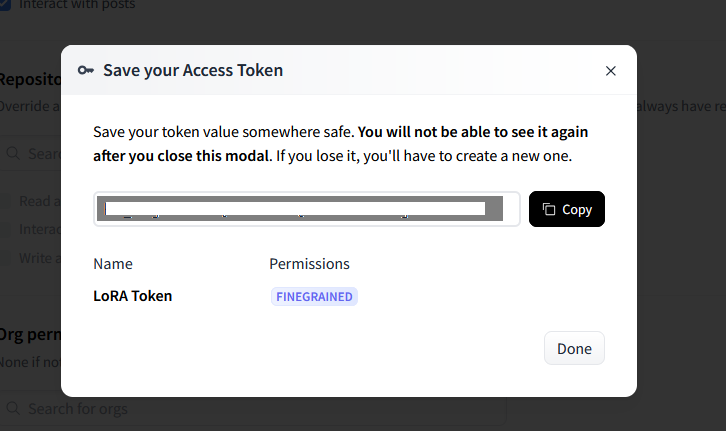
بعد از فشردن دکمهٔ Create Token در انتهای صفحه، یک کُد به شما نمایش داده میشود که همان کد hf_token است. آن را کپی کنید و داخل فیلد hf_token در سایت Replicate قرار دهید.
باقی تنظیمات را بجز آخری دستنخورده بگذارید. برای repo_id، باید دوباره به سایت huggingface برگردید و یک مدل جدید بسازید. این مدل میزبان خروجی سایت Replicate خواهد بود. بعد از وارد کردن اسم دلخواه، مطمئن شوید که مدل شما در حالت Public قرار دارد و آن بسازید.
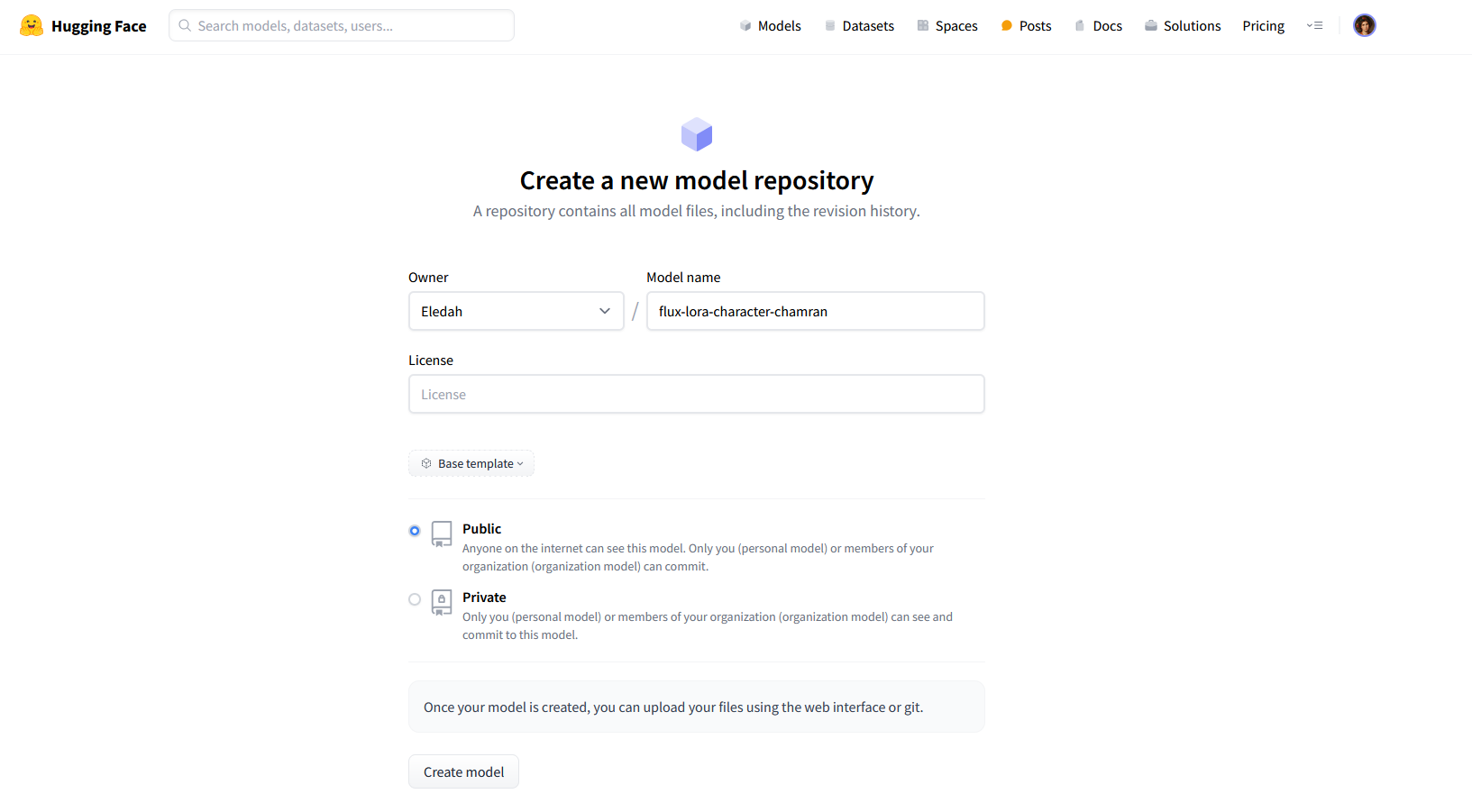
بعد از ساخته شدن مدل، اسم آن را داخل فیلد repo_id به این شکل قرار دهید:
USERNAME/REPONAME
یعنی اول نام کاربری، بعد / و بعد هم نام مدل.
حالا با کلیک روی دکمهٔ Create training، مدل شما به مرور ساخته میشود. ساختن مدل چند ده دقیقه زمان میبرد؛ اما شما میتوانید روند آن را از طریق لاگی که در همان صفحه قرار دارد دنبال کنید. اگر هم اشکال خاصی در مراحل مرتکب شده باشید، در همان لاگ به اطلاع شما میرسد.
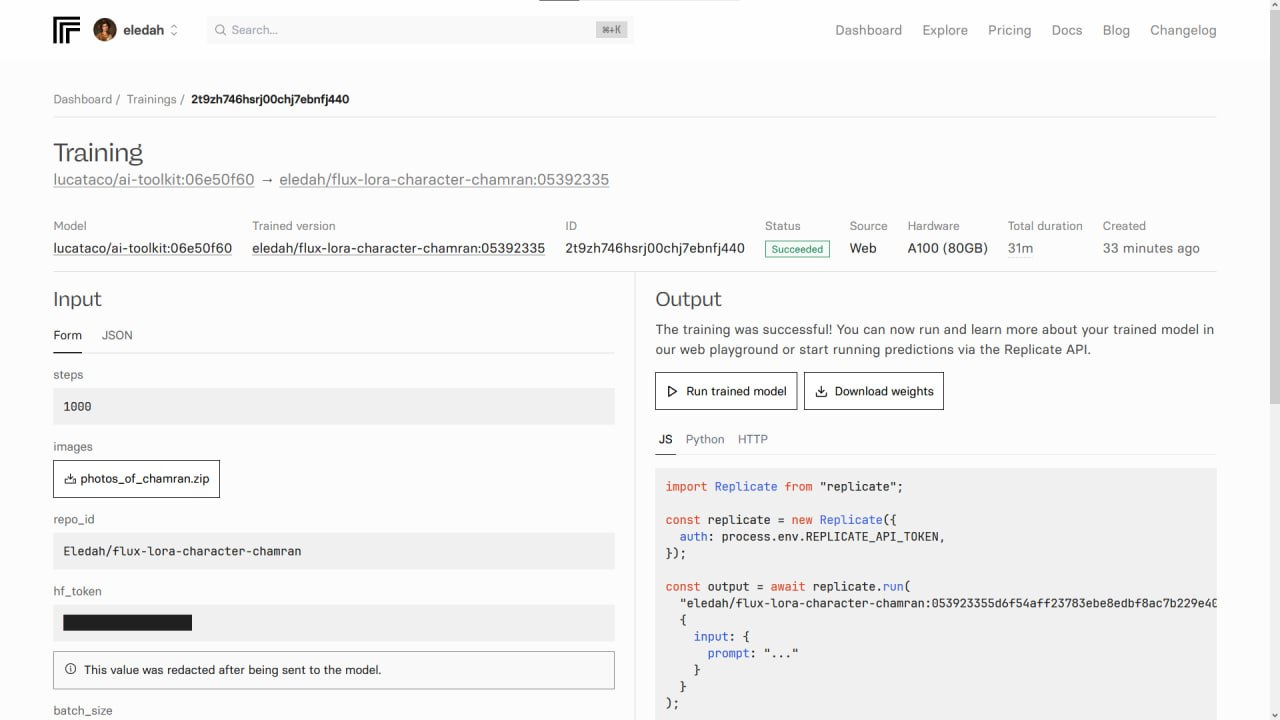
بعد از ساخته شدن مدل، Replicate آن را بر روی اکانت huggingface شما قرار میدهد. با اتمام این کار، حالا نوبت به ساختن تصاویر بر پایهٔ مدل میرسد.
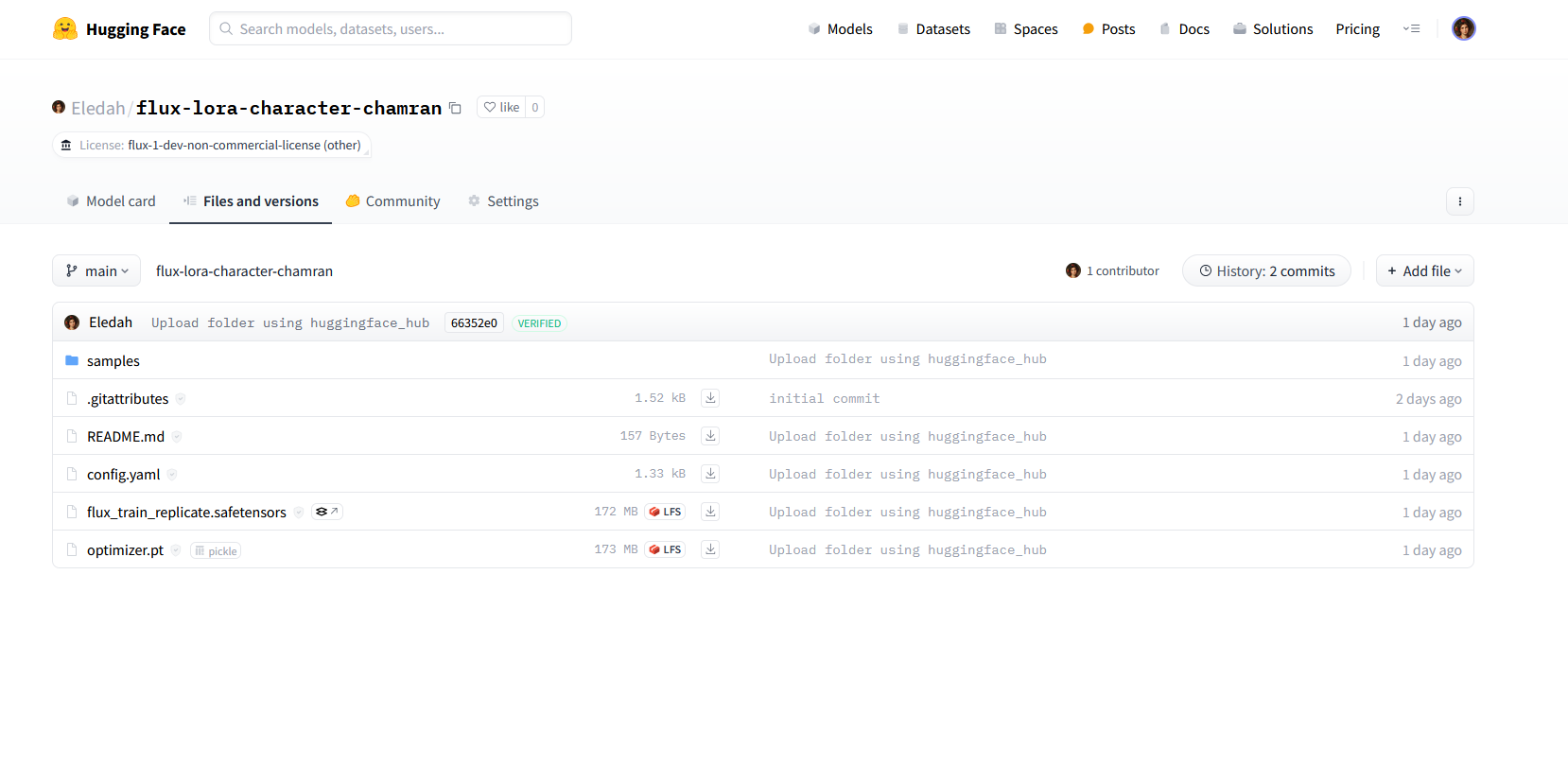
قدم سوم: ساختن تصاویر با مدل
برای ساختن تصویر از مدل روی Replicate به lucataco/flux-dev-lora بروید.
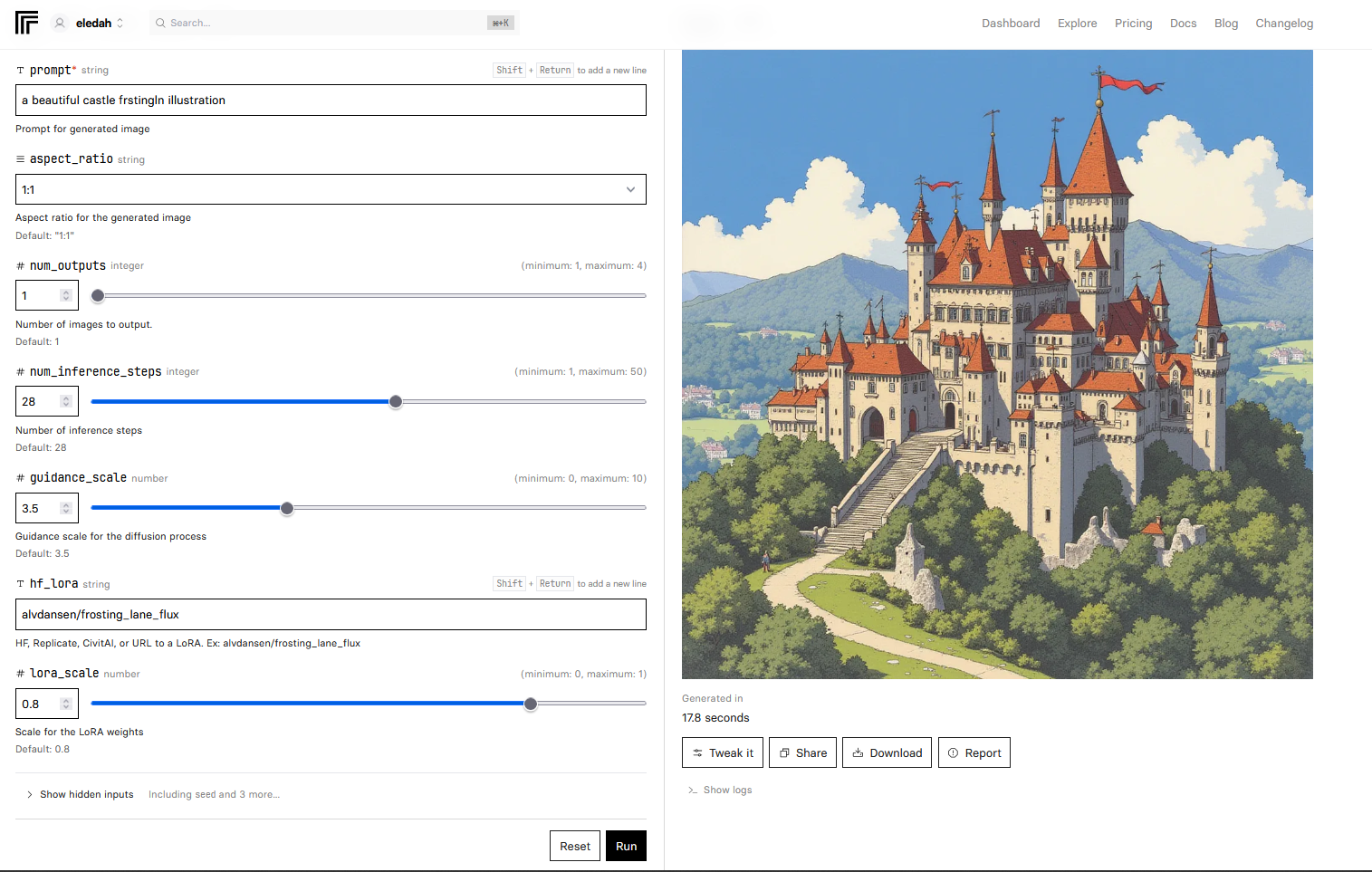
فیلدهای تولید عکس به این شرح است:
فیلد prompt
دستوری است که برای ساخت عکس به مدل میدهید. این فیلد حداکثر ۷۷ توکن برای تولید عکس میپذیرد پس نوشتن پرامپتهای خیلی طولانی کمک نمیکند. برای فراخوانی شخصیتهای خود، به تجربه بهتر است در ابتدای پرامپت از آنها نام ببرید تا انتهای پرامپت. برای بهتر شدن پرامپت همچنین میتوانید از مدلهای زبانی مثل ChatGPT و Claude هم استفاده کنید. مثلاً فرض کنید میخواهیم تصویری از شهید چمران در یک آزمایشگاه فیزیک تولید کنیم. من یک توصیف اولیه برای مدل زبانی مینویسم و از آن میخواهم که آن را برای من بهبود دهد:
Enhance this prompt for me to use in a AI image generator. Use 77 Tokens or less. Provide 5 alternate prompts for me to choose from:
<A quantum physicist in a labcoat doing experiments in a futuristic labaratory>
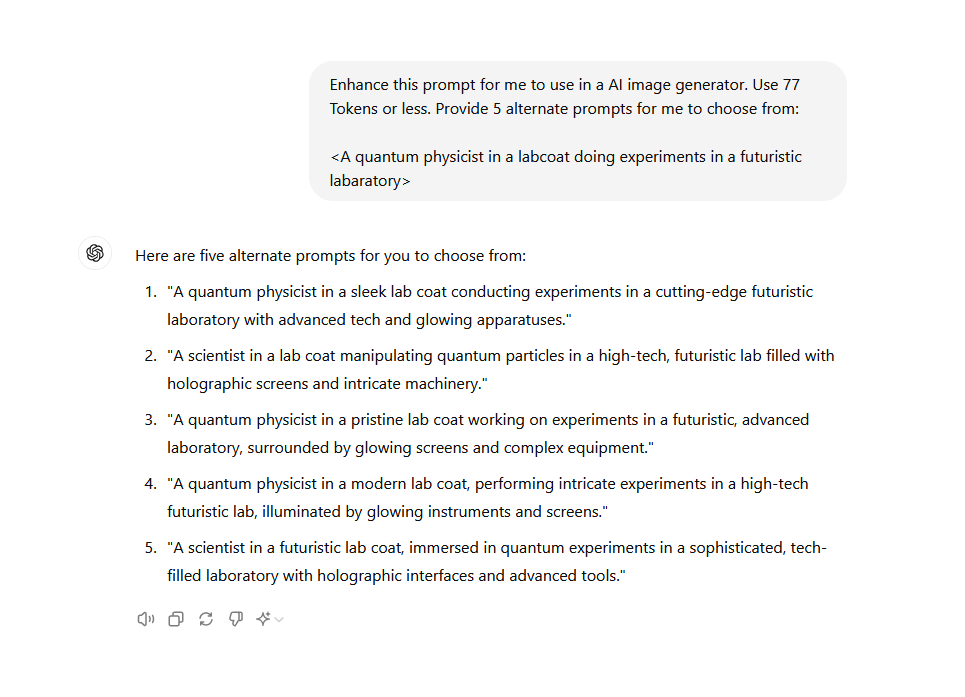
از بین این پرامپتها، یکی را که به نظرم بهتر است را انتخاب میکنم و توکن اختصاصی خودم (chamran) را در آن جا میدهم و آن را در فیلد prompt مدل میگذارم:
Chamran as a quantum physicist in a modern lab coat, performing intricate experiments in a high-tech futuristic lab, illuminated by glowing instruments and screens
فیلد aspect_ratio
نسبت طول به عرض تصویر است. بسته به دلخواه قابل تنظیم است.
فیلد num_outputs
تعداد تصاویر خروجی را مشخص میکند. از آنجایی که تولید هر عکس حدود ۲ هزار تومان آب میخورد، میتوان تعداد بیشتری تولید کرد تا دستمان در انتخاب بهترین عکس بازتر باشد.
فیلدهای num_inference_steps و guidance_scale
نیازی به تغییر این دو فیلد نیست. اولی برای تعداد مراحل نویزگیری از تصویر است و دومی اهمیت پرامپت را در تولید عکس نشان میدهد. مثلاً تصویر زیر تغییرات مقدار guidance_scale را در خروجی نشان میدهد. با افزایش مقدار این متغیر، تصاویر بیشتر بیشتر به سبک دوبعدی و با رنگبندی دلخواه نزدیک میشوند. اما از حد گذراندن آن اکثراً جلوی خلاقیت مدل را میگیرد.

chamran poster with a ak47 in his hands, standing at the top of a mountain with a red sun behind his head, 2d graphic is style of soviet propoganda
فیلد num_of_inference_step تعداد گامهای تدقیق تصویر را تعیین میکند. مدلهای تولید تصویر فعلی اکثراً از یک تصویر رندوم -مثل فریم اول ویدئوی پایین- شروع میکنند و به مرور نویززدایی از تصویر، به خروجی میرسند. عدد ۲۸ که پیشفرض مدل است، برای رسیدن به خروجی راضیکننده کافی است؛ اما اگر خروجی مطلوب شما نبود، این عدد را بالاتر ببرید تا مدل زمان بیشتری صرف ساختن عکسها بکند.
فیلد hf_lora
آدرس huggingface مدلی که ساختهاید. بدون این مدل، flux شخصیتی به نام چمران را نمیشناسد. فرمت آن هم به این شکل است:
USERNAME/REPONAME
فیلد lora_scale
وزن مدل شما در تولید تصویر. وزن ۱ بیشترین و وزن ۰ کمترین تعهد به مدل را دارد. مقدار ۰٫۸ برای آن مناسب است. چرا که گاهی اوقات با وزن ۱ علاوه بر چهره، لباسها هم تکرار میشوند. اگر وزن ۰٫۸ خروجیهای ناسازگاری به شما داد، بهتر است مقدار آن را دستکاری کنید.

chamran impressionist painting with a yellow wheat field behind him, in style of Vincent van Gogh, swirly brush strokes, impressionist art style, vibrant coloring, 8K
فیلد seed
مقدار رندومی که عکس با آن تولید میشود. اگر به دنبال خروجیهای تکراری هستید، seed و پرامپتهای تکراری به مدل بدهید. در غیر اینصورت آن را خالی بگذارید.
فیلد output_format
بهتر است که مقدار آن را به png تغییر دهید.
فیلد output_quality
اگر فرمت خروجی شما png هست، نیازی به تغییر این فیلد ندارید. در غیر اینصورت برای داشتن بهترین خروجی آن را روی ۱۰۰ قرار دهید.
بعد از اعمال تنظیمات، دکمهٔ Run را بزنید. مدل در عرض چند ثانیه تصاویر با چهرهٔ انتخابی برای شما میسازد.

دستکاری متغیرها
حوزهٔ تولید تصویر با هوش مصنوعی همچنان برای سازندگانش هم ناشناخته است. برای همین بهتر است برای رسیدن به خروجی دلخواه، فیلدها را بشناسید و با تغییر آنها، به تصویر مطلوب خود نزدیکتر شوید. ویدئوهایی مثل این که تأثیر فیلدها را با جزئیات بررسی میکنند، کمک بزرگی به رسیدن کاربر به تصویر مطلوبش میکنند.
خلق تصاویر مختلف نیازمند خلاقیت در ایجاد سناریوهاست و دستکاری متغیرهای مدل است. مدلهای زبانی میتوانند در خلق این سناریوها به ما کمک کنند.

مقادیر فیلدهای استفاده شده در تولید عکس بالا:
"input": {
"prompt": "Chamran in white robes, standing in the heart of a vibrant field filled with multicolored flowers. In golden hours of the sky",
"hf_lora": "Eledah/flux-lora-character-chamran",
"lora_scale": 0.9,
"num_outputs": 4,
"aspect_ratio": "16:9",
"output_format": "png",
"guidance_scale": 3.5,
"output_quality": 80,
"num_inference_steps": 28
},علاوه بر مدل flux-dev-lora، میتوانید از مدل flux-dev-schnell هم استفاده کنید. این مدل به ازای هر عکس ۰٫۳ سنت خرج دارد؛ اما در عوض کیفیت عکسهای خروجیاش پایینتر است. تصویر پایین، خروجی مدل schnell با تنظیماتی مشابه عکس بالاست.

ضمیمه ۱: تمرین مدل با کد
اگر اهل برنامهنویسی هستید، کل مراحل بالا را میتوان با کد پایتون هم انجام داد. بخش اول کد پایین، برای شما مدلی در سایت replicate.com با اسم انتخابی میسازد. برای این کار اول از همه باید API_TOKEN خودتان را برای سایت Replicate از این صفحه بردارید و داخل فایلی با نام .env در پوشهٔ کد قرار دهید. به این شکل:
REPLICATE_API_TOKEN=r8_PE*********************************در بخش دوم، برنامه فایل ورودی input.zip را از شما میگیرد و آن را برای مدل میفرستد. برای خروجی مدل میتوانید huggingface را برای میزبانی انتخاب کنید. در این صورت باید از قبل مدل را در huggingface بسازید و مشابه قبل Access Token آن را در داخل کد قرار دهید.
import replicate
import os
from dotenv import load_dotenv
load_dotenv()
replicate.api_key = os.environ["REPLICATE_API_TOKEN"]
# Creating a model
model = replicate.models.create(
owner="USERNAME",
name="MODELNAME",
visibility="public", # or "private" if you prefer
hardware="gpu-t4",
description="A fine-tuned FLUX.1 model"
)
print(f"Model created: {model.name}")
print(f"Model URL: https://replicate.com/{model.owner}/{model.name}")
# Training Phase
training = replicate.trainings.create(
version="ostris/flux-dev-lora-trainer:4ffd32160efd92e956d39c5338a9b8fbafca58e03f791f6d8011f3e20e8ea6fa",
input={
"input_images": open("input.zip", "rb"),
"steps": 1000,
"steps": 1000,
"lora_rank": 16,
"optimizer": "adamw8bit",
"batch_size": 1,
"resolution": "512,768,1024",
"autocaption": True,
"trigger_word": "HAJGH",
"learning_rate": 0.0004,
"hf_token": "HF_TOKEN", # optional
"hf_repo_id": "HF_REPO", # optional
},
destination=f"{model.owner}/{model.name}"
)
print(f"Training started: {training.status}")
print(f"Training URL: https://replicate.com/p/{training.id}")با پایان برنامه، مدل شما در huggingface قرار میگیرد و آمادهٔ استفاده میشود.
ضمیمه ۲: بهینهسازی برای کاربران عادی
طی همهٔ این مراحل برای کاربر عادی نه صرفهای دارد و نه ساده است. راهکار، استفاده از API سایت Replicate و بالا آوردن یک میانجیِ کاربرپسند است. به عنوان مثال برای طی این مراحل با پایتون کافیست با فرستادن فیلدهای درخواستی به سایت، خروجی را دریافت کرد:
import replicate
input = {
"prompt": "Chamran in white robes, standing in the heart of a vibrant field filled with multicolored flowers. In golden hours of the sky",
"hf_lora": "Eledah/flux-lora-character-chamran",
"lora_scale": 0.9,
"num_outputs": 4,
"aspect_ratio": "16:9",
"output_format": "png",
"guidance_scale": 3.5,
"output_quality": 80,
"num_inference_steps": 28
}
output = replicate.run(
"lucataco/flux-dev-lora:a22c463f11808638ad5e2ebd582e07a469031f48dd567366fb4c6fdab91d614d",
input=input
)
print(output)
#=> ["https://replicate.delivery/yhqm/U0JjGgdA6E4NBB8RRfSXv0q...همهٔ این اقدامات کافیست در بکاند سایت انجام شود و کاربر تنها مقادیر aspect_ratio و prompt را در فرانت تغییر دهد تا خروجیهای خود را ببیند.