من کیام؟
سلام 👋 من محمدعلی هستم. ۲۸ ساله از تهران.
برای ارتباط، تلگرام پیام بدین و برای آشنایی، صفحهٔ بریدهها، آیههای مورد علاقه و ادامهٔ همین متن رو ببینید.
علوم و نظریههای مورد علاقهٔ من
نظریهها لنزهایی هستند که در دیدن واقعیت به ما کمک میکنند. نگاه من هم به پدیدهها اغلب الهامگرفته از این لنزهاست:
۱. دائوئیسم و پدیدارشناسی: من این دو را شبیه هم میدانم. خلاصهٔ برداشت من این است که زبان، کلمات، تفسیر و فکر کردن ما را از واقعیت و ذات پدیدهها دور میکند. برای اینکه بتوانیم بهتر به حقیقت برسیم، گاهی لازم است که بیواسطه با پدیدهها روبرو شویم. البته که همهٔ دائوئیسم و پدیدارشناسی این نیست؛ دائوئیسم مباحثی دربارهٔ زوجیت یا حکمرانی دارد که آن را هم مهم میدانم.
۲. نظریهٔ ساختارگرایی: کل دنیا به هم مرتبط است. بخشی از وجود اجزا، در گرو وجود اطرافیان آن است، معنی هر کلمه، در گرو معانی باقی کلمات است. روابط میان اجزاست که ساختار را میسازد؛ نه تکتک اعضا. این نگاه ریشههای عمیقی در عرفان شرقی دارد اما در قرنهای اخیر در تفکر غربی هم ظهور پیدا کرده است.
۲.۱. نظریهٔ سیستم: اجزاء یک کل منسجم میسازند که بیشتر از جمع تکتک اجزاست. ترجمهٔ ساختارگرایی در علوم مهندسی است. بخش نظریهٔ سیستم در این بلاگ به همین نظریه میپردازد.
۲.۲. نظریهٔ فرمالیسم ادبی: این لنز ترجمهٔ ساختارگرایی در نقد ادبی است. هر چقدر اصطکاک میان اجزا کمتر و هماهنگی میان آنها بیشتر باشد، اثر زیباتر است. داخل متن هنر نمونههایی از تبیین این نظریه وجود دارد.
۳. نظریهٔ روانکاوی فروید: مدلی برای توضیح روبنا و زیربنای روان انسان است. البته که دیگر جایی در آکادمی ندارد و شبهعلم محسوب میشود؛ اما راه خودش را داخل زبان روزمرهٔ ما و شاخههای علوم انسانی باز کرده است. آنچه از روانکاوی برای من جذاب است، نیروهای ناخودآگاهی است که انسان را بدون فکر به سمتوسوهای مختلف میکشاند.
۴. نظریهٔ سیگنال یا نظریهٔ علامتدهی: منتج از نظریهٔ تکامل است. اصل حرف نظریه این است که موجودات زنده برای افزایش شانس بقا و تولید مثل خودشان، سیگنالها و نشانههایی به محیط اطراف خودشان میفرستند. مثلاً قورباغههای سمی رنگهای جیغ دارند. یا حیوانات نر کلی آیین و مناسک مخصوص دارند که به مادهها قدرت و سرزندگی خودشان را نشان بدهند. در مورد انسانها هم همین است. کتاب The Elephant in the Brain به همین میپردازد. متن Signaling as a Service هم با مثالهای دقیق ادبیات را توسعه میدهد و ربط این نظریه را با شبکههای اجتماعی مشخص میکند.
۵. نظریهٔ نمایشی گافمن: بخش بزرگی از واقعیتی که میبینیم اجرا و تئاتر است. این نظریه جامعه را شامل یک سکوی جلو صحنه، یک پشت صحنه و یک جایگاه تماشاگران در نظر میگیرد و نقشهای مختلفی را در این تئاتر ترسیم میکند1 و ادعا میکند که واقعیت اجتماعی در تعامل روزمره میان افراد آن ساخته میشود.
یک نمونه
پاییز ۱۴۰۴ که لوکیشن اکانتهای توییتر شفاف شد، دیدم که عدهٔ کثیری از موافقان و مخالفان فیلترینگ، موافقان و مخالفان حکومت، اخلاقیها و ضداخلاقیها همه اینترنت بدون فیلتر (اصطلاحاً سیمکارت سفید) داشتند. با نگاه گافمن، این شفافیت مثل بالا رفتن ناگهانی پردههای نمایش تئاتر بود. ما وقتی نمایش را میبینیم یا فیلمش تماشا میکنیم، نمیفهمیم که آیا ویژگیهایی مثل خشم در ذات بازیگر است یا در ظاهر او. تنها وقتی به حقیقت دست پیدا میکنیم که در محیطی جدا از صحنهٔ نمایش با او برخورد داشته باشیم. بالا رفتن پرده در اینجا ذات خیلی از افراد را مشخص کرد. عجیبتر این بود که عدهای بعد از لو رفتن، طلب حلالیت و معذرتخواهی کردند یا عدهای فرار رو به جلو کردند. اما واکنشهای پسینی خیلی مهم نیست. چرا که دوباره در نقش خودشان فرو رفتهاند.
۵.۱. نظریهٔ نهادگرایی اجتماعی: منتج از نظریهٔ نمایشی گافمن و کتاب ساخت اجتماعی واقعیت است. این نظریه جامعه را حاصل تعامل نهادهایی اصلی میداند که هر کدام سازوکارهای بقا، انتشار و تبادل مخصوص خودشان را دارند. مثل خانواده، دین، حرفه، سیاست و…
پروژهها
پروژههای شخصی، کامل یا ناقص، حالتِ فیزیکیِ علایقِ غیرفیزیکی من هستند.
پروژهٔ کریستالین
که همینجاست. کریستالین 🔮 یعنی شفاف. شفافیت در نوشتن باعث عیان شدن مقصود نویسنده میشود. زبان گفتگوی ما به مرور دچار آفت پیچیدگی -به سردمداری آکادمیکها- و بیمعنایی -با محوریت سیاستمداران- شده است. اگر بیان فصیح (بدون ابهام) و صریح (بدون تعارف) قد علم نکند، عقلی که پیروی زبان است هم دچار پیچیدگیهای بیش از حد و پوچی معنایی خواهد شد.
کل داستان با یک کانال آپارات شروع شد. دلیل شروع کردنش تجربیاتی بود که طی چند سال از یادداشتنویسی داشتم. قبل از شروع کانال هم گشته بودم و منبع مناسبی -بهخصوص فارسی- برای اصل نوشتن پیدا نکردم. به مرور زمان کریستالین توسعه پیدا کرد و حالا یک کانال تلگرام و بلاگ هم دارد. کانال تلگرام صرفاً محلی برای اطلاعرسانیهای کانال است؛ اما سایت بازهٔ بزرگتری را دربرمیگیرد.
داخل سایت نوشتههای طولانیتر من -که هیچ ربطی به ویدئوهای آپارات ندارند- و پروژههای جستهگریختهٔ شخصی وجود دارد. وجه مشترک مطالب سایت، حضور دائمی آنها در ذهن من است که مدام به آنها ارجاع میدهم. برای همین هم یک دور آنها را مینویسم که هم ذهن خودم مرتبتر باشد و هم ارجاع دادن به آنها سادهتر و کاملتر باشد.
گوی شیشهای به صورت کاملا ناخودآگاه و اتفاقی جزو اولین نمادهایی بود که برای کار و سایت انتخاب کردم. اما الان که برمیگردم و میبینم، معنایش برایم واضح میشود. رسالت فعلی من جادو و کیمیاست. معانی کلماتی مثل ثروت، سیاست، تبلیغات در زندگی روزمره برایم به گند کشیده شدهاند و باعث قهر کردنم با آنها شده است؛ که ثروت مایه فساد و سیاست نمایش تئاتر و تبلیغات ابزار تحمیق است. طلاهای دنیا در نظرم مس شدهاند و آنها قهر کردهام. قهر، بیتحرکی میآورد. پس وقت آن رسیده که دست به کیمیا بزنیم. اتفاقاً ماده اولیه کیمیا همین سرب و لجنهایی است که به اسم سیاست و دین و اقتصاد گفتهاند. باید گداخته شود و اکسیری بر آنها بیفتد تا درمان شوند. باید جور دیگری دید و آتشی تازه برافروخت که اول مایه دلگرمی خود است و دوم مایه سوزاندن لجنها و ایجاد فضایی برای رشد جوانهها.
مطالب بلاگ با هدف دستهبندی خاصی نوشته نشدهاند؛ اما بعد از چند سال بهنظرم دستههای اصلی و متنهای اصلی هر دسته، از جزء به کل، اینها هستند:
- لایهٔ میکرو (ارتباط با خود): اتوبوس ذهن، رشد، زیرزمین روح، دینداری، آیین و زادگان تناقض
- لایهٔ مِزو (ارتباط با دیگری): باغچهٔ آقای عطایی، انفصال بدن و اختلاف نظر، اتاق ۴۱۲، هدیه و استعداد
- لایهٔ ماکرو (ارتباط با ساختار): اختگی و نوزادگی، جراح، معمار و میزبان، علیه کاهنان و تف سربالا
- لایهٔ جهان (ارتباط با فرهنگ و زبان): نویز، چراغ قرمز دوم، صحبت جنگ، بنچمارک و تنظیم پرسپکتیو
- لایهٔ متا (ارتباط با فرم و پیچیدگی): هنر، هلو و پیاز، ابرفرمالیسم، امپرسیونیسم، پورنوگرافی و سری دیزاین
🥳 این پروژه در حال توسعه است.
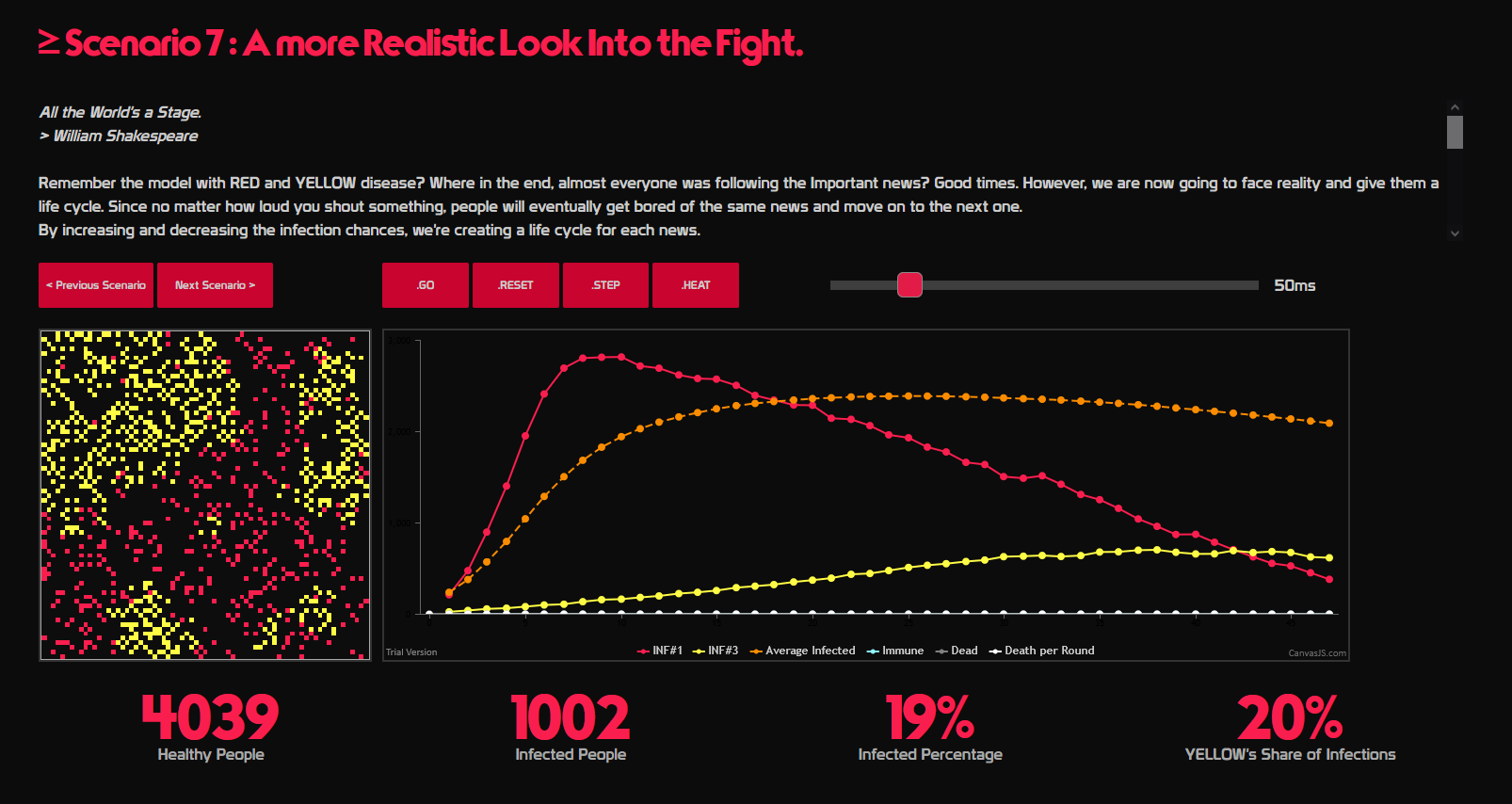
پروژهٔ شبیهسازی انتشار بیماری (دمو)
این پروژه را آذر ۱۳۹۸ شروع کردم. یعنی حدود ۳ ماه قبل از همهگیری کرونا در ایران و دقیقاً زمان اعلام اولین موارد کرونا در دنیا! هدفم از این پروژه ربطی به خود بیماری نداشت. بلکه میخواستم از شیوع بیماری به عنوان استعارهای برای شیوع اخبار و شایعات استفاده کنم و ببینم که آیا میشود رویدادهای روزمره رسانهای را با مدلهای بیماری مدل کرد یا نه. نتیجهاش شد سایت disEase.
داخل سایت سناریوهای مختلف -عمدتاً مرتبط با فضای رسانهای- وجود دارد که هر کدام شرایط خاص خودشان را دارند. مثلاً برای رشد و مرگ تدریجی شایعهها، در ابتدا نرخ شیوع بیماری از عدد پایین ناگهان رشد میکند و سپس کاهش پیدا میکند (سناریوی ۶). در یک سناریوی پیچیدهتر، قدرت شایعه به جنگ قدرت بیانیه و اصلاحیه میرود. همانطور که در دنیای واقعی زور شایعات به حقیقت میچربد، در مدل هم اتفاقات مشابهی میافتد (سناریوی ۷).
 |
|---|
✅ این پروژه پایان یافته و توسعهٔ آن متوقف شده است.
پروژهٔ رصد قیمتهای دیجیکالا (دمو)
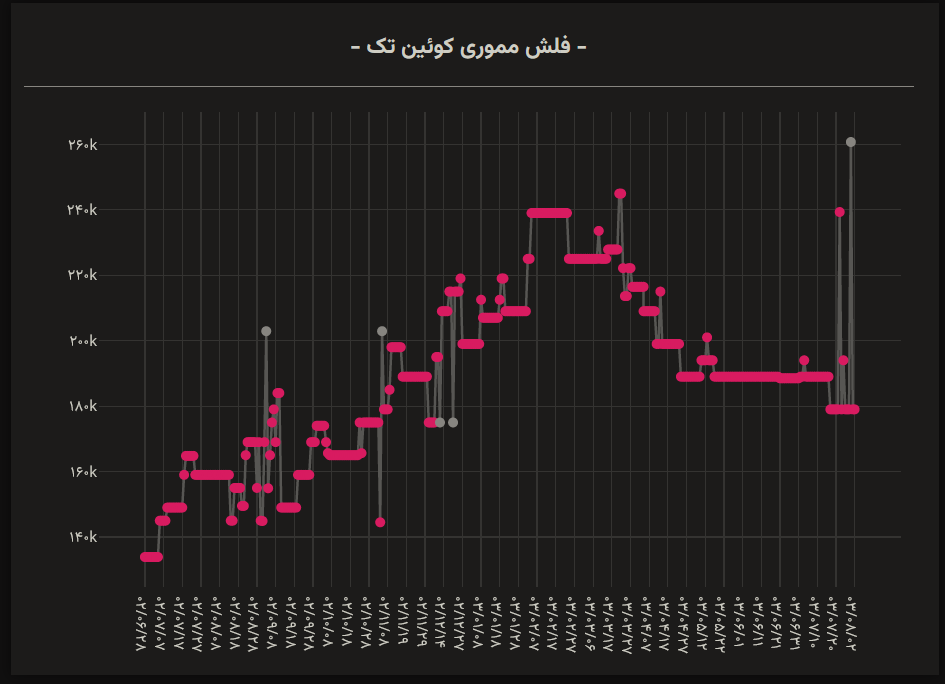
این پروژه را شهریور ۱۴۰۲ شروع کردم. هدفم از این پروژه، مشاهدهٔ تغییر قیمت کالاها در طول زمان بود. خیلیها از بالا رفتن قیمتها مینالیدند و از طرف دیگر معلوم بود که زندگیشان تغییر خاصی نکرده است. میخواستم ببینم بالاخره این قیمتها بالا میروند یا نه و اصلاً چقدر بالا میروند. به چندتا از دوستان اقتصادخواندهام پیام دادم و فهرست کالاهای مهم را ازشان گرفتم (مال مرکز آمار بود). علاوه بر آنها، کالاهایی که خودم به قیمتشان حساس بودم را اضافه کردم. اول از همه میخواستم از نمودار قیمت خود سایت دیجیکالا استفاده کنم؛ اما نمودارشان فقط اطلاعات یک ماه را نشان میدهد (معلوم است چرا) و بیکیفیت طراحی شده است. به یکی از دوستان دیگرم که آنجاست هم برای اصلاح نمودار قیمت پیشنهادهایی دادم؛ اما هنوز که هنوز است تغییری ایجاد نشده. به خاطر همین تصمیم گرفتم خودم سایتش را بزنم. خروجیاش شد pMonitor.
داخل سایت نمودارهای قیمت برای چندده کالای مختلف که در دیجیکالا فروخته میشود وجود دارد. محور افقی تاریخ و محور عمودی قیمت را نشان میدهد. با کلیک روی عنوان محصول، به صفحهٔ فروشش در دیجیکالا هدایت میشوید. نقاط قرمز نمودار قیمت متعلق به تخفیف هستند. با انتخاب بخش خاصی از نمودار با موس، میتوانید تغییرات قیمت را در آن بازهٔ خاص مشاهده کنید. بازههایی که در آن قیمتی وجود ندارد، به خاطر ناموجود بودن کالا یا بازی درآوردنهای سایت دیجیکالاست.
 |
|---|
دیدن خود نمودارها گویای اتفاقات بازار هست. اما اگر فرصتی پیدا کنم، حتما دربارهٔ نمودارهای عجیب و غریب تغییر قیمت دیجیکالا مینویسم. برای اینکه منظور من را بهتر بفهمید، نمودارهای تغییر قیمت این اجناس را ببینید:
- نیمبوت زنانهٔ چرم مشهد
- کتاب در نهایت هر دو میمیرند
- عطر مردانهٔ ساواج دیور
- ژل شستشوی صورت لافارر
- ساعت هوشمند مدل K59Pro
✅ توسعهٔ این پروژه متوقف شده است؛ به دلیل سیاست دیجیکالا در تغییر مداوم فرمت ارائهٔ قیمتها، زمان کافی برای بهروزرسانی مدام آن را ندارم.
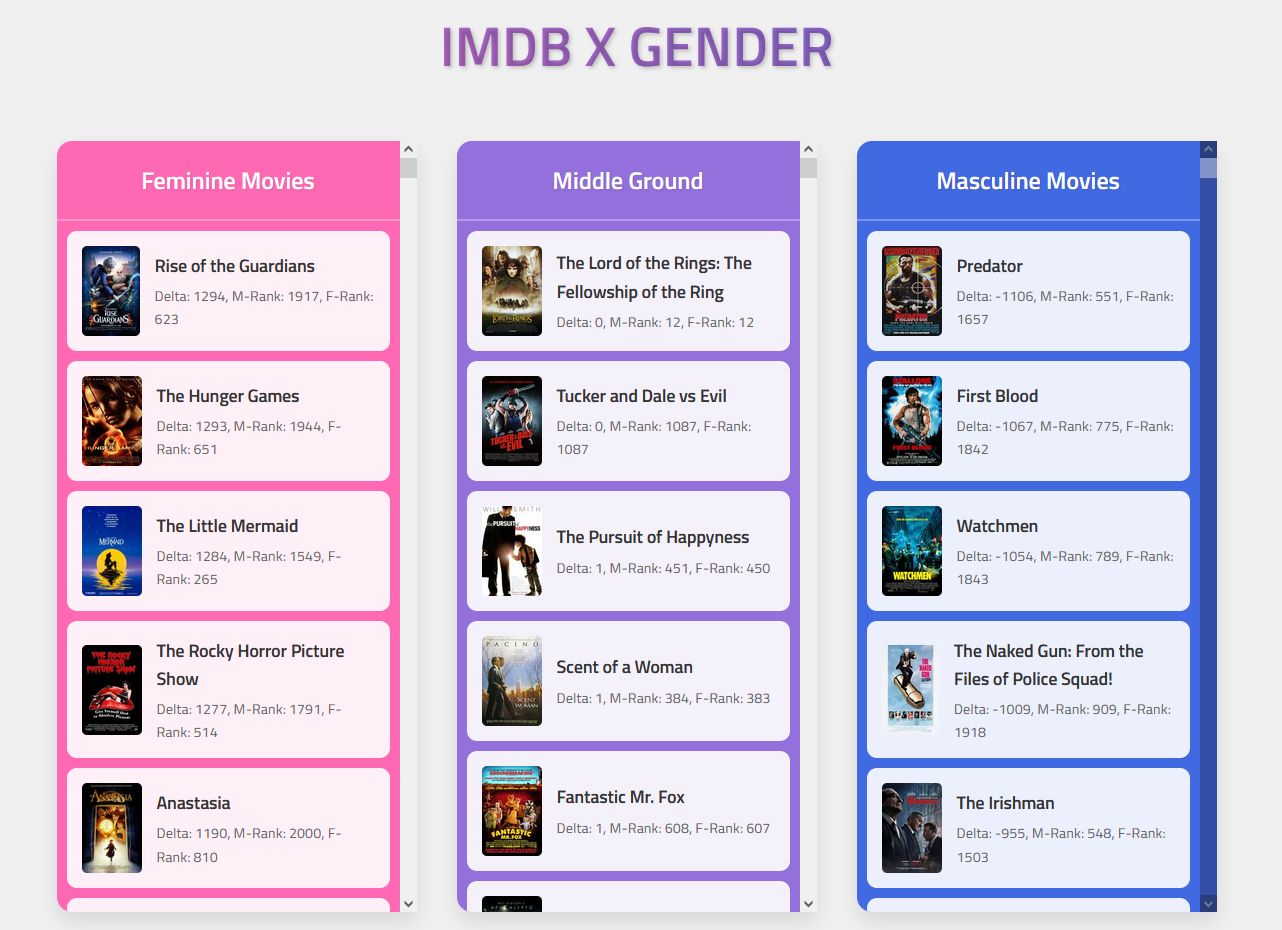
پروژهٔ رتبهبندی فیلمها بر اساس جنسیت (دمو)
سایت IMDB قبلتر ویژگی جالبی داشت که برای هر فیلم، امتیاز را به تفکیک ردهٔ سنی و جنسیت هم نشان میدهد. یعنی معلوم بود که مردان بالا ۴۵ سال یا زنان بین ۱۸ تا ۲۹ سال در مجموع چه نمرهای به یک فیلم دادهاند. این قابلیت در نسخهٔ جدید سایت حذف شده است. اما فروردین ۱۴۰۰ که من این پروژه را شروع کردم، این نمرهها هنوز وجود داشتند.
در جریان این پروژه ۲۰۰۰ فیلم اول IMDB را انتخاب کردم و تمامی نمرههایشان را برای همهٔ ردههای سنی درآوردم. در مرحلهٔ بعدی نمرهٔ میانگین هر فیلم را بر اساس تعداد و نمرهٔ گروههای سنی محاسبه کردم و بر اساس این نمرهٔ میانگین، فیلمها را رتبهبندی کردم. مثلاً رتبهٔ فیلم «هفت سامورائی» بین مردان ۱۹ و بین زنان ۱۰۹ است. یا رتبهٔ فیلم «پرسونا» بین مردان ۳۰۲ و بین زنان ۱۸۶ است. برای راحتی بیشتری، متغیری به نام دلتا تعریف کردم که فاصلهٔ رتبهٔ مردان و زنان را نشان میدهد. دلتای مثبت به معنی «زنپسندی بیشتر» و دلتای منفی به معنی «مردپسندی بیشتر» فیلم است. فیلمهایی هم که دلتای نزدیک به صفر دارند، به اندازهای یکسان توسط مردها و زنها پسندیده شدهاند.
برای نمونه، دلتا و رتبهٔ چند فیلم معروف را این زیر مینویسم:
| فیلم | دلتا | رتبهٔ مردان | رتبهٔ زنان |
|---|---|---|---|
| ۱۲ مرد خشمگین | ۲- | ۸ | ۱۰ |
| نجات سرباز رایان | ۲۵۲- | ۲۸ | ۲۸۲ |
| غرور و تعصب | ۱۰۱۰ | ۱۲۲۳ | ۲۱۳ |
| طناب | ۲- | ۴۰۱ | ۴۰۳ |
| شبکهٔ اجتماعی | ۸۳۴- | ۶۶۳ | ۱۴۹۷ |
| منِ نفرتانگیز | ۵۵۸ | ۱۰۷۴ | ۵۱۶ |
خروجی جدولی این پروژه از طریق گوگل شیت قابل دسترسی است. در کنار جدول، یک سایت تروتمیز هم با کمک هوش مصنوعی برای نشان دادن خروجیهای پروژه نوشتهام که بسته به جمع، میتواند به انتخاب فیلم کمک کند.
 |
|---|
✅ این پروژه به پایان رسیده و توسعهٔ آن متوقف شده است.
پروژهٔ قرآن در مارکداون
ایدهٔ اصلی این پروژه از ویدئوی Bible Study: How Joschua uses the LYT frameworks آمده است. یکی از کاربران نرمافزار ابسیدین راه سادهای برای ترکیب انجیل با قابلیتهای نرمافزار پیدا کرده است. کاربران مسلمان هم از این قضیه الگو گرفتند و راهی برای آوردن قرآن به داخل والت خودشان طراحی کردند. نمونههایی از این راهها در این گفتگوی فروم موجود است.
فعالیت من از خرداد ۱۴۰۱ شروع شد. یک کد سادهٔ پایتون نوشتم که با کمک API سایت alquran.cloud سورهها، آیهها و ترجمههای آنها را بگیرد و داخل فایلهای md قرار دهد. در این حالت -مشابه کار Joschua- برای هر آیه یک هدینگ اختصاصی وجود دارد که ارجاع دادن به آن را ساده میکند. مثلاً کاربر با نوشتن ![[سورة الأنعام#148]]، آیهٔ ۱۴۸ سورهٔ انعام را برای نمایش فراخوانی میکند و در یادداشتهایش به این شکل آنها را میبیند:
سَيَقُولُ ٱلَّذِينَ أَشْرَكُوا۟ لَوْ شَآءَ ٱللَّهُ مَآ أَشْرَكْنَا وَلَآ ءَابَآؤُنَا وَلَا حَرَّمْنَا مِن شَىْءٍۢ ۚ كَذَٰلِكَ كَذَّبَ ٱلَّذِينَ مِن قَبْلِهِمْ حَتَّىٰ ذَاقُوا۟ بَأْسَنَا ۗ قُلْ هَلْ عِندَكُم مِّنْ عِلْمٍۢ فَتُخْرِجُوهُ لَنَآ ۖ إِن تَتَّبِعُونَ إِلَّا ٱلظَّنَّ وَإِنْ أَنتُمْ إِلَّا تَخْرُصُونَ
بزودی مشرکان (برای تبرئه خویش) میگویند: «اگر خدا میخواست، نه ما مشرک میشدیم و نه پدران ما؛ و نه چیزی را تحریم میکردیم!» کسانی که پیش از آنها بودند نیز، همین گونه دروغ میگفتند؛ و سرانجام (طعم) کیفر ما را چشیدند. بگو: «آیا دلیل روشنی (بر این موضوع) دارید؟ پس آن را به ما نشان دهید؟ شما فقط از پندارهای بیاساس پیروی میکنید، و تخمینهای نابجا میزنید.»
✅این پروژه به پایان رسیده و توسعهٔ آن متوقف شده است.
پروژهٔ خط زمانی ایران (دمو)
ایدهٔ اصلی این پروژه دورادور از متن ساختار ساختارها از دکتر کدکنی گرفته شده است. یک نکتهٔ اصلی این مقاله، همزمانی بزرگان ایران است. یعنی کم پیش میآمده که مشاهیر ما پراکنده از هم رشد کنند هر شاخهٔ علمی پیشرفت خودش را بکند. همه با هم پیشرفت میکنند و هیچگاه تکروی وجود نداشته است.
حدود قرن چهارم عصری است که ساختار ساختارها در اوج است و بنابراین همه ساختارهای کوچک تر چون شعر، نثر، موسیقی، عرفان، طب و معماری نیز در جایگاه بلندی قرار دارند.
اما رابطه و همزمانی بین مشاهیر هیچجا به ما گفته نشده است. برای خود من جالب بود که ابنسینا، فردوسی، جوینی، شیخ طوسی، ابوسعید ابوالخیر، باباطاهر، نظامالملک، ابونصر منصور، ابن بابویه و ابوالفضل بیهقی همگی همعصرند. پروژهٔ خط زمانی با کنار هم قرار دادن مشاهیر ایران در یک محور افقی، نشان میدهد که ساختاری بزرگتر از تکتک شاخههای علم و هنر وجود دارد و در صورت کارکرد آن است که این ساختارهای کوچکتر پیشرفت میکنند.
 |
|---|
دادههای این پروژه از سایت pantheon.world آمدهاند که آن هم از ویکیپدیا به عنوان مرجع استفاده میکند. به دلیل جلوگیری از شلوغی سایت، افرادی که اهمیت کمتری داشتهاند حذف شدهاند.
✅ این پروژه به پایان رسیده و توسعهٔ آن متوقف شده است.
پروژهٔ مکالمه
از مشکلات رسانههای امروزی، جهتگیری افراطی و ایجاد اتاقهای پژواکی است که حرفهایی تکراری در آن مطرح میشود. اگر هم بنا باشد در این رسانهها نقلی از حرف مخالفان بگویند، بدترین و ضعیفترین استدلال آنها را طرح میکنند تا مایهٔ تحقیر و تمسخر شود؛ نه راهی برای درک طرف دیگر ماجرا. تشدید این قضیه، شکافها را عمیقتر میکند.
یک راه خروج از این اتاقهای پژواک، دستیابی به حرف اصلی و قویترین استدلال طرف مقابل و سپس گفتگو دربارهٔ آن است. اما با ساختار فعلی و جریان درآمدی رسانههای فعلی، امیدی به آنها ندارم. رسانههایی مثل آزاد (مدرسهٔ آزادفکری سابق) و برنامههایی مثل شیوهٔ شبکهٔ ۴ تلاش برای شکلدهی این گفتگوها میکنند؛ اما آنها هم به خاطر قرارگیری در میان بازیهای رسانهای، باز رو به حرفهای سطحی و شعاری میآورند و کم میشود که گفتگویی واقعی در آن شکل بگیرد.
پیشنهاد من برای چنین شرایطی، اضافه کردن «حافظه» به ساختار فعلی است؛ چرا که اگر حافظه وجود نداشته باشد، حرفهای قدیمی مدام تکرار میشوند. بحث فیلترینگ قبلتر سر دستگاه ویدئو، بعدش سر ماهواره، حالا سر اینترنت و فردا سر ماجراهای دیگر تکرار خواهد شد؛ اما هر بار همان حرفهای قدیمی از دو سر طیف شنیده میشود. تا جایی که انسان فکر میکند شاید مسألهٔ اینها اصلاً حل معضل نیست و چیز دیگری است.
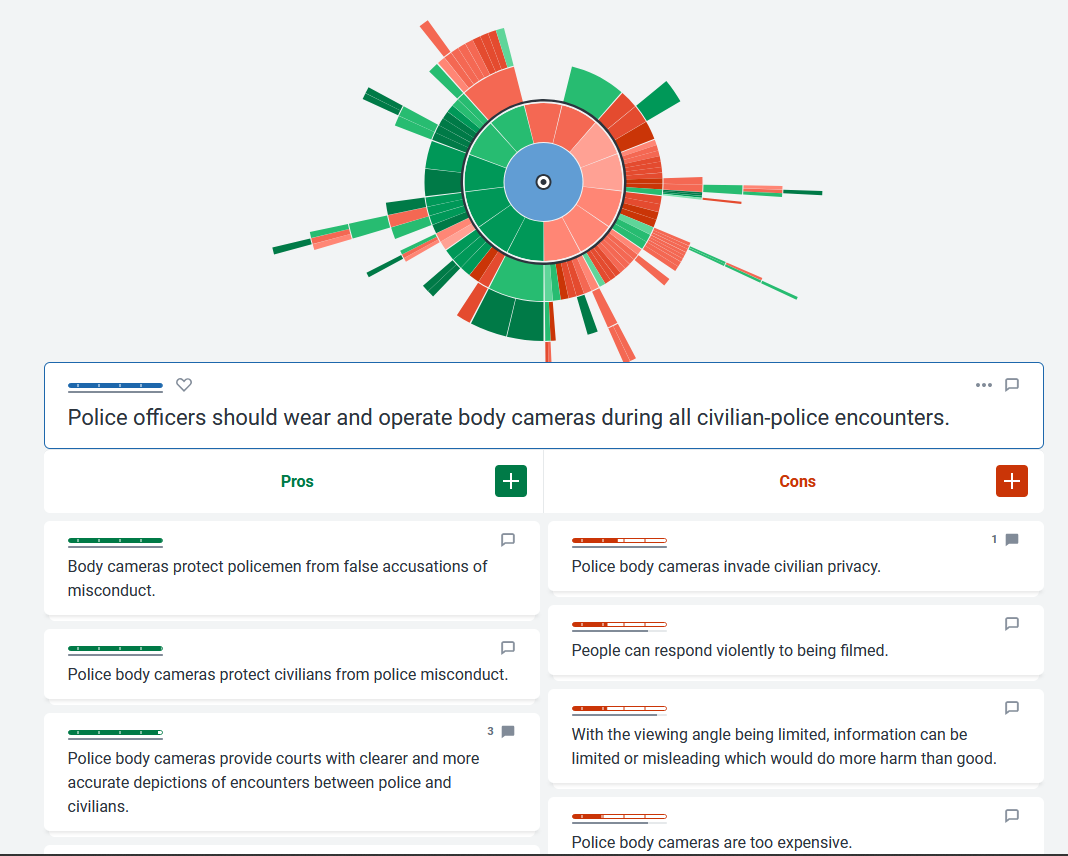
یک راه برای حافظهدار کردن گفتگوها، پیادهسازی آن در قالبی قابل دسترس است. پروژهٔ مکالمه با الهام از سایت kialo همین هدف را دنبال میکند. خود kialo از تکنیک نقشهٔ برهان یا Argument Mapping استفاده میکند تا همهٔ استدلالهای موجود در رد و تأیید یا گزاره را در نقشهای بزرگ به نمایش بکشد. حول هر گزاره استدلالهایی وجود دارد و برای هر استدلال هم گزارههای موافق و مخالف نوشته میشوند. با تکمیل تدریجی این نقشه، کل بحث از درون اذهان خارج میشود و به روی زمین میآید. در این صورت است که هر کسی با مطالعهٔ گزارهها میتواند جهتگیری خود را با آگاهی بیشتری تعیین کند و درگیر نویز رسانهها نشود.
 |
|---|
پروژهٔ مکالمه هم دقیقاً هدف را دارد. منتها موضوع مکالمههای آن به بحثهای روز و شکافهای تاریخی ایران میپردازد. منبع گزارههای این پروژه، گفتگوهایی مطرح شده در رسانه و آرشیو مسابقات مناظره است.
🥳 این پروژه در حال توسعه است
Footnotes
-
مدل کار و پژوهش اروینگ گافمن را میپسندم چون از نزدیک و بیواسطه با مسأله مواجهه شده است. در کتاب «فلسفههای پژوهش کیفی» دربارهاش اینطور آمده است: «در کارهای تجربیِ خود به شدت به انواع دادههای تجربی اتکا میکرد. او با زنان خانهدار مصاحبه کرد؛ جامعهای در یک جزیره را از طریق قومنگاری عمیق بررسی نمود؛ محاکمات و مشکلاتِ زندگی بیماران در یک موسسه روانپزشکی را با استفاده از مشاهده مشارکتیِ پنهان مورد تحقیق قرار داد؛ در نقش یک دیلر (پخشکننده کارت) در کازینویی در لاسوگاس بازی کرد تا ابعاد قمار در تعامل انسانی را مستند و استخراج کند؛ او به برنامههای رادیویی گوش میداد، ضبط و تحلیلشان میکرد؛ و او کم و بیش آزادانه از هرگونه تکنیک کیفی، چه رسمی و چه غیررسمی، برای دستیابی به غنای سرشار زندگی اجتماعی استفاده میکرد». ↩