بهینهسازی مدلهای موجود زمانی لازم میشود که اطلاعات موردنظر ما در دیتاستهای آموزش مدلها موجود نباشند. این عدم وجود اغلب به خاطر تخصصی یا تازه بودن اطلاعات است. برای حل این مشکل و فهماندن اطلاعات به مدلها، دو رویکرد اصلی وجود دارد: Retrieval-Augmented Generation (RAG) و Fine-tuning1.
استفاده از رویکرد RAG زمانی بهصرفه است که دقت اطلاعات خروجی برای ما مهم باشد. اگر دقت مهم نیست و صرفاً کلیتی مدنظر ماست -مثلاً اینکه مدل به سبک یک نویسندهٔ خاص صحبت کند- بهتر است از فاینتیونینگ استفاده کنیم.
تکنیک RAG
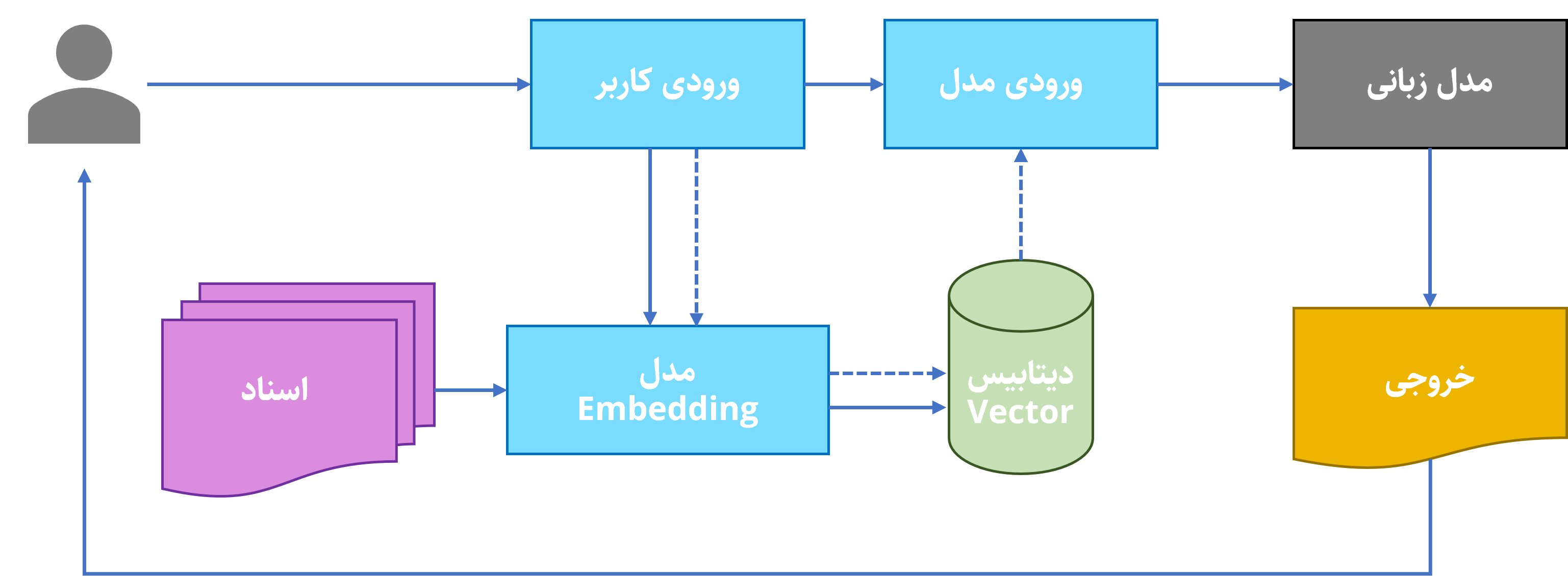
به زبان ساده، RAG اسناد مرتبط را از ما میگیرد و تلاش میکند که محتویات هر یک را بفهمد. بعد از فهمیدن، با هر بار درخواست کاربر، سیستم RAG اسناد مرتبط با درخواست را پیدا میکند و آنها را در کنار درخواست اولیهٔ کاربر (مثل تقلب) به مدل زبانی میدهد.
 |
|---|
تکنیک RAG به صورت محلی
پیادهسازی سیستم RAG با ابزارهای موجود به نسبت ساده است. در ادامه پیادهسازی یک سیستم ساده RAG با کمک Ollama و Open WebUI و سپس پیادهسازی آن را با زبان python میبینیم.
نصب Ollama دشواری خاصی ندارد. با مراجعه به صفحهٔ دانلود آن نسخهٔ موردنظر را انتخاب، دانلود و نصب کنید. برای نصب Open WebUI هم بعد از نصب python و pip، کافیست دستور pip install open-webui را در ترمینال اجرا کنید تا نصب آن کامل شود.
بعد از نصب نرمافزارهای موجود، نوبت به دریافت مدل میرسد. فهرست مدلهای موجود Ollama در این صفحه قابل مشاهده است. ما در این مدل برای سادگی کار، با مدل Llama 3.1 کار میکنیم. برای دریافت این مدل، دستور ollama pull llama3.1 را در ترمینال اجرا میکنیم.

حالا که مدل و رابط کاربری هر دو آماده هستند، نوبت به اجرای آنها میرسد. با اجرای ollama run llama3.1 مدل در ترمینال اجرا میشود. برای راهاندازی رابط کاربری هم ابتدا دستور open-webui serve را اجرا کنید و بعد از طریق آدرس http://localhost:8080 در مرورگر آن را باز کنید.
 |
|---|
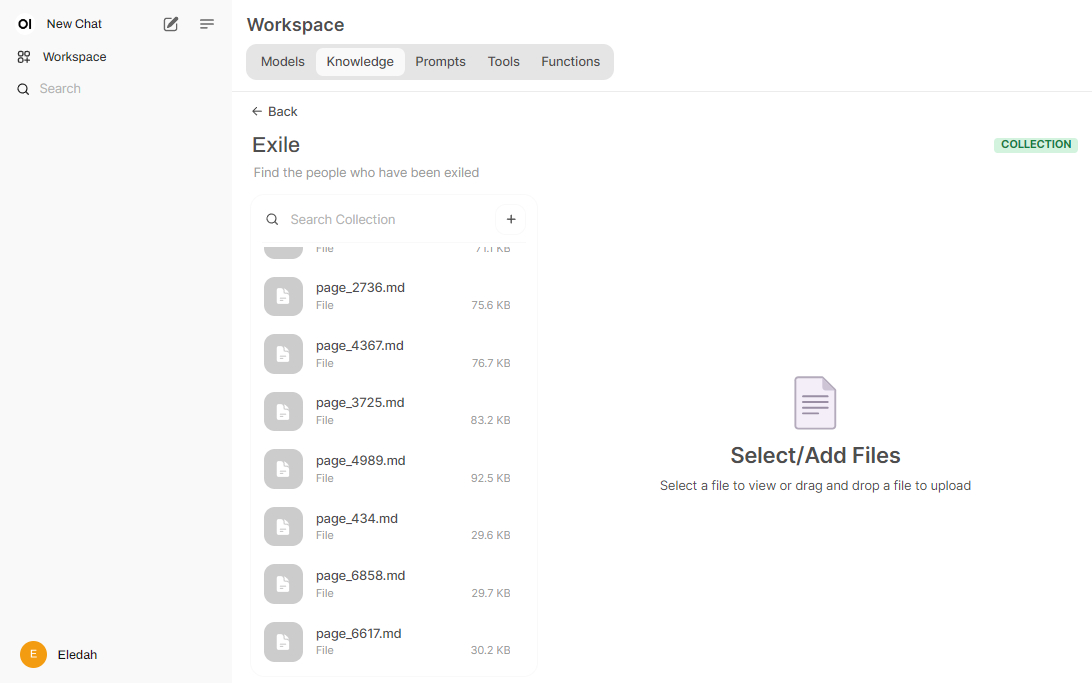
ابزار Open WebUI قابلیت دریافت اسناد و اجرای RAG را دارد. برای اضافه کردن فایلها، به منوی Knowledge بروید و یک پوشهٔ جدید ایجاد کنید. سپس آدرس فایلهای خود را به آن بدهید تا فایلها را یکی یکی Embed کند. زمانی که این فرآیند به پایان رسید، به صفحهٔ اصلی Open WebUI برگردید و اینبار دستور خود را با @ وارد کنید تا اطلاعات جدید در پاسخ مدل فراخوانی شوند.
 |
|---|
دقت پاسخهای مدل به چند عامل بستگی دارد. عامل اول، دقت مدل Embedding در طبقهبندی اسناد است. اگر مدل Embedding با زبان اسناد بیگانه باشد، طبقهبندی دقیقی هم از آنها نخواهد داشت. یکی از چالشهای فعلی پیادهسازی RAG در زبان فارسی، نبود مدل Embedding مناسب است. عامل دوم دقت خود مدل است. اگر مدل Embedding هم عالی کار کند و مرتبطترین اسناد را به مدل ورودی بدهد، خروجی کار مثل ریختن سوخت جت در ژیان میشود. در صورت قوت همزمان هردوی این مدلهاست که خروجی RAG کیفیت مطلوب را خواهد داشت.
تکنیک RAG به صورت برخط
راه دیگر برای پیادهسازی سیستم RAG، استفاده از ابزارهای موجود در وب است. به عنوان مثال، قابلیت Custom GPT از OpenAI این اجازه را به ما میدهد تا با بارگذاری فایلهای مختلف، یک چتبات اختصاصی ایجاد کنیم که دستورهای خاصی میگیرد و با ارجاع به فایلهای ما، پاسخهای دقیقتری در اختیار کاربر میگذارد.
مثلاً در جریان انجام پروژهای، ابتدا کلیهٔ اسناد مرتبط با تبعیدهای قبل از انقلاب را جمعآوری کردم و بعد از مرتبسازی، آنها را در قالب ۱۰ فایل در اختیار چتبات جدیدم گذاشتم. علاوه بر فایلها، توضیحاتی هم دربارهٔ چگونگی تعامل با کاربر برایش نوشتم.
 |
|---|
خروجیهای این چتبات به هیچ وجه رضایتبخش نبود. دسترسی به اسناد یا اینترنت هم نتوانست دقت پاسخها را بالا ببرد و برعکس باعث توهم چتبات در تولید جوابهای غیرواقعی شد.
 |
|---|
 |
|---|
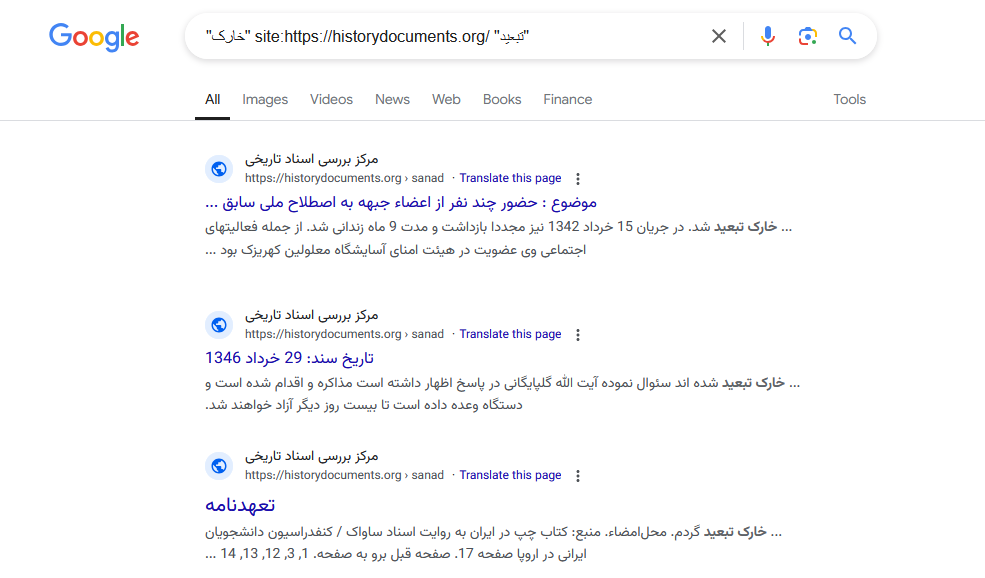
پس در حال حاضر با یکی از بهترین ابزارهای هوش مصنوعی، امکان گفتگو با اسناد مهیا نیست. با این اوصاف بهتر است که از تکنولوژیهای دیگری برای جستجو در اسناد استفاده کنیم. یک نمونهٔ آن استفاده از موتورهای جستجو و نوشتن برنامهای برای پردازش متنها و استخراج جداول است. در این حالت کاربر به جای پرسیدن سؤالی به زبان انسانی، با یک query در جدول میتواند به اطلاعات دلخواه خود برسد.
 |
|---|
یک راه دیگر که هنوز آزموده نشده است، توسعهٔ یک سیستم RAG از ابتدا و بدون واسطه است. در این حالت تمامی قدمها از جمله تشکیل Vector DB و کلیهٔ فرآیندهای Embedding با کدنویسی انجام میشوند و امکان دارد که دقت خروجی در این حالات بیشتر باشد.
Footnotes
-
البته که راه سومی هم وجود دارد و آن ساخت یک مدل از پایه است. اما این راه به دلیل حجم بالای پردازشی و اطلاعاتی، به هیچ وجه در مقیاسی جز مقیاس ملی صرفه ندارد. ↩