در بحث یادگیری ماشین فرآیند Embedding -که برای آن ترجمههای تعبیه کردن، جاساز کردن و نشاندن را آوردهاند- به تبدیل اشیاء به بردارهایی چندبعدی گفته میشود. Embedding نوعی طبقهبندی است که با هدف فهماندن مفاهیم نزدیک به هم به ماشین انجام میشود.
توضیح فرآیند
برای فهمیدن مفاهیم نزدیک به یکدیگر، ویژگیهای مختلف مقسم اشیاء و موجودات زنده ذکر میشود. به هر کلمه، مفهوم یا فایل ذیل این ویژگیها عددی اختصاص پیدا میکند که شدت آن ویژگی را میسنجد. در گام بعدی و در صورت نیاز، این ماتریس چندبعدی به فضایی با بعدهای کمتر نگاشت میشود تا تفاوتهای بین مفاهیم بهتر آشکار شود1.
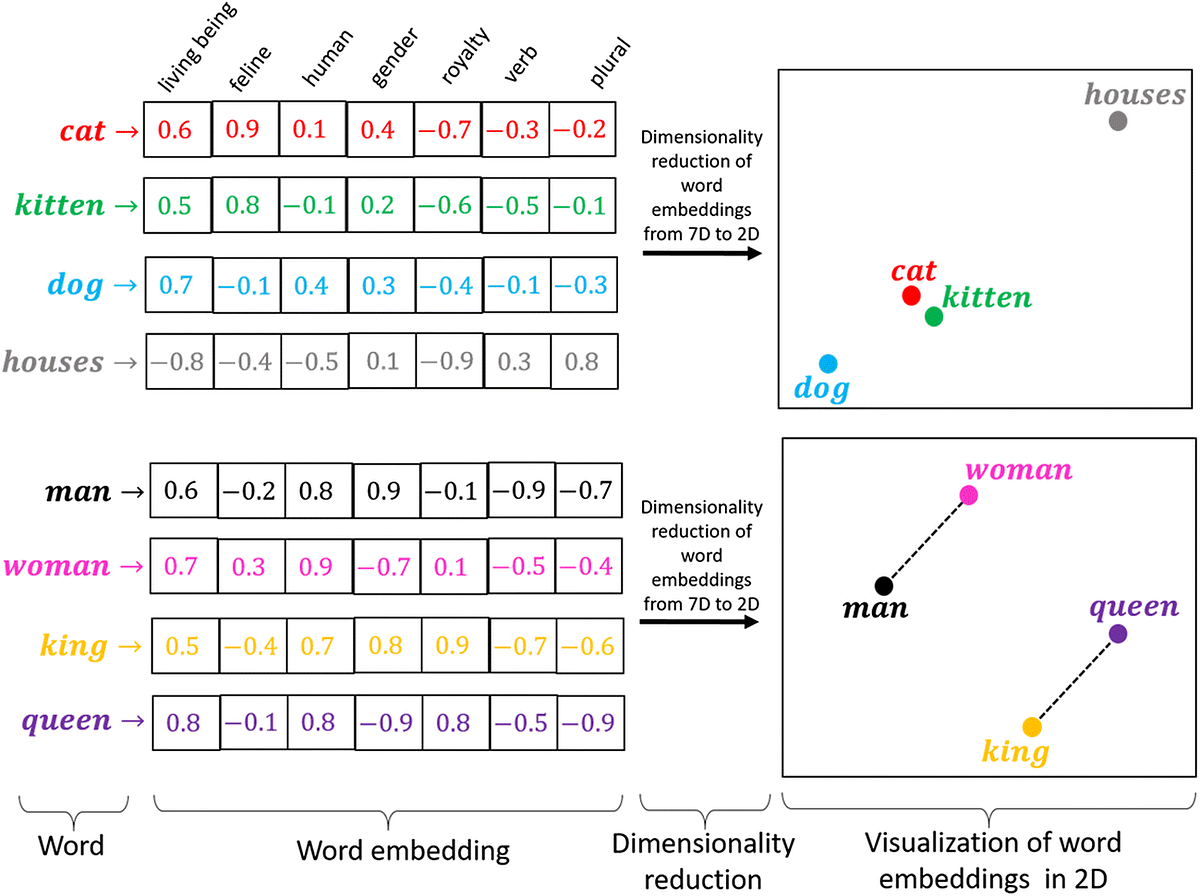
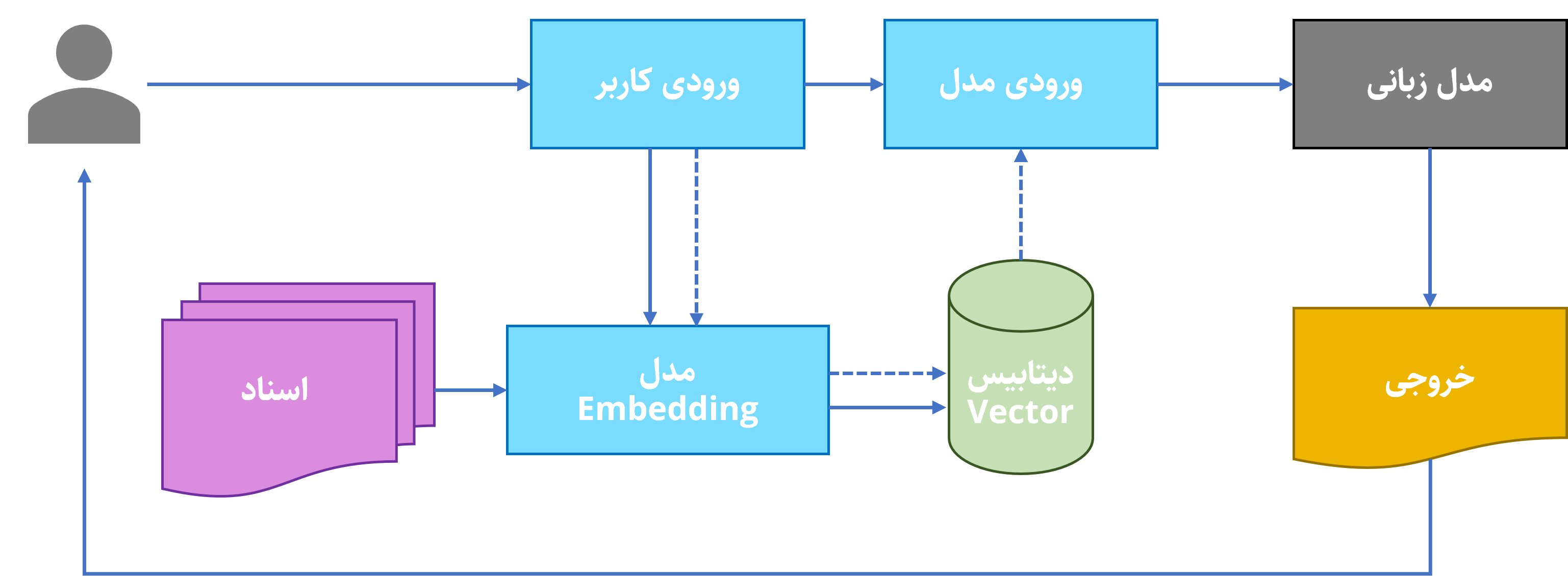
کاربردهای Embedding
یکی از استفادههای اصلی Embedding، موتورهای پیشنهاددهنده2 هستند که بر اساس پسندهای کاربر، محصولات جدید را به او پیشنهاد میکنند. کاربرد دیگری که به تازگی به قابلیتهای Embedding اضافه شده است، دستهبندی اسناد است. در اجرای فرآیند RAG مدلهای Embedding ابتدا فایلهای ورودی را دستهبندی میکنند و سپس بر اساس دستور کاربر، نزدیکترین فایلهای مربوط به درخواست را در کنار اصل درخواست به عنوان ورودی به مدل زبانی میدهند.
 |
|---|
رنکینگ مدلهای Embedding از این لینک قابل مشاهده است.
نمونهٔ اجرای Embedding
برای مشاهدهٔ بهتر با این مدلها، یک نمونه از آنها را اجرا میکنیم. مدل مورد استفادهٔ ما word2vec-skipgram-fa-wikipedia است که توسط تیم HezarAI با دادههای ویکیپدیا آموزش داده شده است. این مدل قابلیتهای مختلفی از جمله تبدیل کلمه به بردار (همان مقادیر عددی)، یافتن کلمات مشابه، کلمات غریبه در بین کلمات مشابه و تعیین نزدیکی میان دو کلمه را دارد.
اول از همه برای استفاده از این مدل، باید پکیج آن را در محیط پایتون نصب کرد:
pip install hezar
و سپس با بارگیری مدل، دستورهای مرتبط را فراخوانی کرد:
from hezar.embeddings import Embedding
w2v = Embedding.load("hezarai/word2vec-skipgram-fa-wikipedia", bypass_version_check=True)دستور اول، مابهازای برداری کلمات را در اختیار ما میگذارد. آرایهٔ زیر که شامل دهها عدد مختلف است، همان برداری است که کلمهٔ «مهندس» را توصیف میکند.
# Get embedding vector
vector = w2v("مهندس")
print(vector)
[array([ 0.07285673, 0.5035447 , -0.33388057, -0.06195636, -0.02063869,
-0.6039401 , -0.03637085, 0.1218688 , 0.05062489, -0.08126286,
-0.19882321, 0.38288993, 0.47926652, 0.18169892, 0.07058148,
-0.3271213 , 0.41374114, -0.03950172, 0.12716956, -0.06809922,
-0.23815873, 0.1368336 , -0.6932135 , 0.08205401, 0.27756432,
-0.32543343, -0.27169392, 0.02598408, 0.17573655, -0.08605785,
0.09510966, 0.5612869 , 0.14946608, 0.8418886 , 0.5877771 ,
-0.44654655, -0.68858045, -0.15175173, 0.15072474, -0.09656956,
-0.0193308 , 0.08146638, 0.0826563 , -0.2597222 , -0.27821398,
-0.05938119, -0.20767985, -0.17503433, 0.28212708, 0.1338007 ,
0.53060836, -0.04736216, -0.23199819, 0.23073475, 0.3244552 ,
0.41777065, -0.26655364, 0.09169614, 0.21735683, 0.08157235,
-0.17562115, 0.2862412 , 0.13502292, 0.02109295, 0.08220951,
0.13489214, 0.09700231, -0.24976304, -0.06363361, -0.02198161,
-0.20557176, 0.6826964 , -0.10924668, -0.28040677, -0.00735047,
-0.30580398, -0.13903758, 0.45955554, 0.36609644, -0.59660155,
0.5077454 , -0.17502798, -0.15826626, 0.21949685, 0.22887215,
-0.3645925 , 0.04743662, 0.2739934 , -0.34535855, 0.06276405,
0.18808143, -0.1557157 , -0.2955405 , -0.05371932, 0.3021156 ,
0.24715178, 0.23305982, 0.21868722, 0.12291432, -0.19192459,
-0.03206363, -0.12900496, -0.45171428, 0.23666364, -0.14136899,
0.31928778, -0.65779966, -0.00378273, 0.24822772, -0.13829629,
0.46043143, -0.02270651, -0.14840993, 0.30670422, 0.18777768,
-0.0111748 , -0.12936208, 0.21609914, -0.25628945, -0.5426224 ,
0.4685646 , -0.03595901, -0.05241607, 0.37473527, 0.10143746,
-0.5083266 , 0.41436222, -0.151693 , -0.23039635, 0.40277562,
-0.16882436, 0.53888917, -0.17260626, -0.09645078, -0.1930386 ,
0.02946973, -0.3411566 , -0.9505491 , -0.25001195, 0.51857334,
-0.06944835, 0.05997254, 0.28484514, 0.3202631 , 0.1502704 ,
-0.02819194, -0.07670471, -0.28135997, -0.39233038, -0.21551238,
-0.17192139, 0.0985023 , 0.05378347, 0.0769344 , -0.64524746,
-0.03999722, 0.55209464, 0.2801474 , 0.12301169, 0.12189167,
-0.07439602, 0.23193054, 0.25362772, 0.17114252, 0.18398815,
0.10809934, -0.17923042, -0.12653765, 0.4414899 , 0.086789 ,
0.17187437, -0.13323785, 0.4407511 , -0.01324347, -0.10020013,
-0.02883745, 0.05466582, -0.12227941, -0.07939242, -0.07356498,
0.05540658, 0.00293058, 0.29997212, 0.04316332, -0.15722567,
-0.5116247 , -0.03843522, -0.02476316, 0.03601353, 0.69141656,
-0.5766813 , -0.07552605, -0.32164854, -0.25757894, -0.45193964,
0.21247187, -0.09750253, -0.32628283, 0.1565887 , 0.01231408],
dtype=float32)]دستور بعدی، کلمهٔ ناهمگن را مشخص میکند. این دستور بین کلمات ورودی همانی را انتخاب میکند که کمترین خوانش را با دیگر کلمات دارد.
# Find the word that doesn't match with the rest
doesnt_match = w2v.doesnt_match(["خانه", "اتاق", "ماشین", "باغچه"])
print(doesnt_match)
ماشیندستور سوم، برعکس دستور بالا، نزدیکترین کلمات را به کلمهٔ ورودی پیدا میکند و آن را خروجی میدهد:
# Find the top-n most similar words to the given word
most_similar = w2v.most_similar("مهندس", top_n=5)
print(most_similar)
[{'word': 'بازرگان', 'score': '0.6575'}, {'word': 'بلومه', 'score': '0.6356'}, {'word': 'کارافرین', 'score': '0.6331'}, {'word': 'شهرساز', 'score': '0.6306'}, {'word': 'حشره\u200cشناس', 'score': '0.6262'}]و در نهایت دستور آخر میزان قرابت بین دو کلمه را نشان میدهد:
# Find the cosine similarity value between two words
similarity = w2v.similarity("مهندس", "دکتر")
print(similarity)
> 0.5121578
similarity_2 = w2v.similarity("مهندس", "آفتاب")
print(similarity_2)
> 0.03668214