تکنیک RAG منابع جدیدی را در اختیار مدل میگذارد تا از آن در تولید خروجی استفاده کند. درست مثل اینکه قبل از پرسیدن سؤال از یک دانشآموز، کتاب درس را در کنارش قرار بدهیم. در تکنیک RAG، بر خلاف فاینتیونینگ پارامترهای مدل دستنخورده باقی میمانند. مثلاً اگر مدلی مثل Llama 3.1 را به اسناد تاریخی متصل باشد، پیش از پاسخگویی آن اسناد را مطالعه میکند و پاسخی که میدهد دقت بالاتری دارد.
این روش در مقایسه با فاینتیونینگ دقت بالاتر و هزینهٔ کمتری دارد و زمانی استفاده میشود که پاسخهای مدل به کاربر نیازمند دقت و برپایهٔ اسناد موجود باشند.
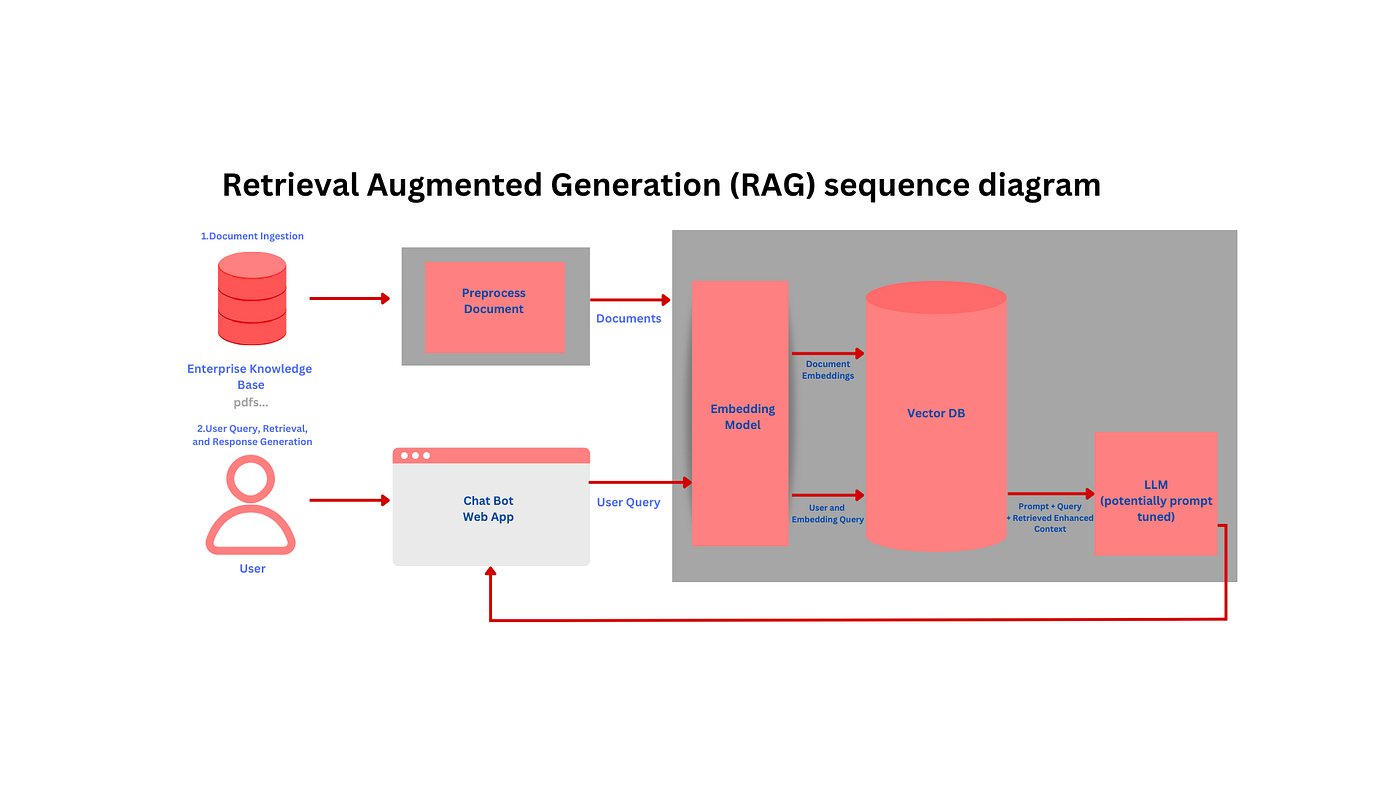 |
|---|